DeepConf can greatly reduce computational effort in language model reasoning tasks

Meta and UC San Diego have introduced DeepConf (Deep Think with Confidence), a new inference method designed to make mathematical reasoning in language models faster and more accurate.
So-called reasoning language models usually break down tough problems by generating multiple solution paths, then picking the answer that comes up the most. But every path gets equal weight, even when some are clearly wrong. That means a weak but frequent solution can win out, while each extra path adds computational cost without always improving the answer.
How models show their uncertainty
DeepConf tackles this by measuring how sure the model is about each prediction. When the model puts most of its probability on a single next word, it's signaling confidence in that path. If it's unsure, the probability gets spread out over many options. The more focused the probabilities, the higher the model's confidence. The research team found that these high-confidence paths are much more likely to be correct.
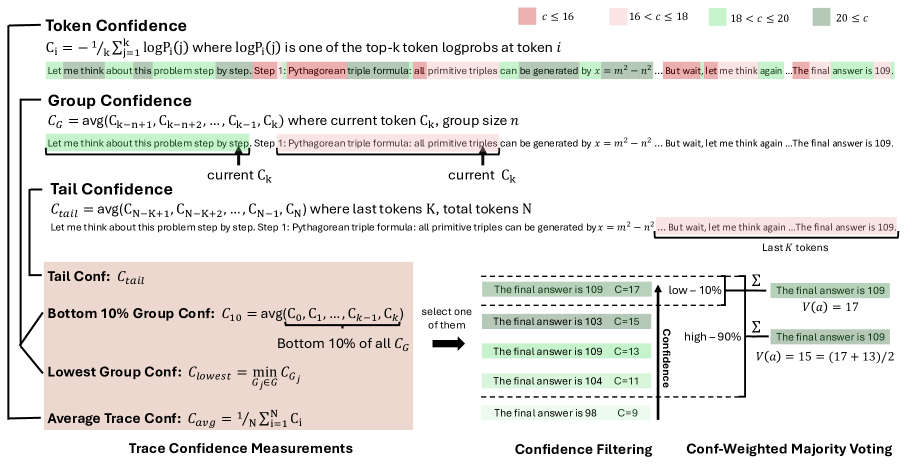
Most older methods just averaged confidence across the entire reasoning chain. DeepConf takes it further by analyzing individual sections, making it easier to spot and remove weak links or error-prone segments.
Two operating modes
DeepConf comes with two modes. In offline mode, it generates all reasoning paths up front, then filters or down-weights the low-quality ones before choosing a final answer. In online mode, DeepConf checks confidence as each solution path is generated and stops early if confidence drops below a certain threshold. That threshold is set using 16 reference paths. The aggressive version benchmarks against the top 10 percent, while the conservative one uses the top 90 percent.
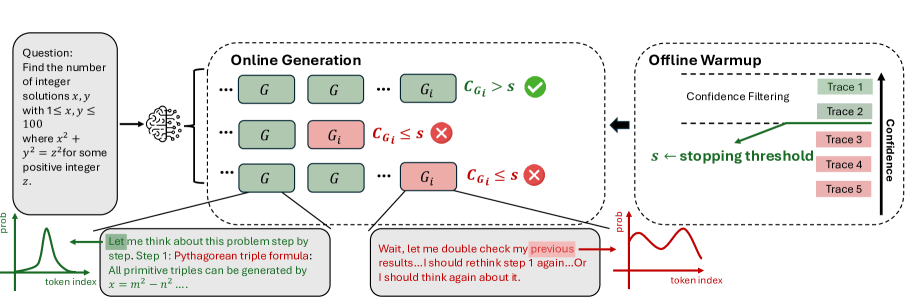
The researchers put DeepConf to the test on five open-source models, from Deepseek-R1-8B up to gpt-oss-120B, using math competitions like AIME24/25, HMMT25, and BRUMO25, along with scientific reasoning tasks.
On AIME 2025, DeepConf reached 99.9 percent accuracy in offline mode with gpt-oss-120B. In the leaner online mode, it still hit 97.9 percent accuracy and slashed token usage by 84.7 percent compared to regular majority voting.

Each experiment was run 64 times to ensure the results were statistically solid. In math tasks, the aggressive setting cut token usage by as much as 84.7 percent, while the conservative mode saved up to 59 percent, typically without sacrificing accuracy. These reductions are measured across all tokens generated in every run, so the savings are especially noticeable when lots of weak solution paths get stopped early.
DeepConf doesn't require extra model training and can be dropped into systems like vLLM with just a few lines of code.
Limitations and outlook
There are some limits. If a model is very confident in a wrong answer, DeepConf might not filter it out, especially in aggressive mode. The researchers recommend the conservative version for more stable results, even if it's a bit less efficient. The code is available on GitHub.
Reasoning models have become the go-to for getting reliable answers from AI. OpenAI, for example, routes harder questions to a special "thinking" mode in GPT-5, though this switch doesn't always work as intended.
Some studies now question if investing in "thinking" models is worth it, especially with rising energy costs. Approaches like DeepConf, which match or beat standard accuracy with much less computation, could play a key role in the future of language models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.