Deepseek OCR 2 cuts visual tokens by 80% and outperforms Gemini 3 Pro on document parsing
Key Points
- Deepseek has released Deepseek OCR 2, a vision encoder that processes image information based on content context, requiring only 256 to 1,120 tokens per image—significantly fewer than comparable systems.
- The model achieves 91.09 percent on the OmniDocBench benchmark, marking an improvement of 3.73 percentage points over its predecessor.
- Researchers view the architecture as a step toward standardized multimodal encoders that could eventually process text, speech, and images within the same basic framework.
Chinese AI company Deepseek has unveiled a new vision encoder that rearranges image information based on meaning rather than processing it in a rigid top-to-bottom, left-to-right pattern.
Traditional vision-language models chop images into small sections and process them in a fixed order, starting from the top left and moving to the bottom right. According to Deepseek's researchers, this approach doesn't match how humans actually see. Our eyes follow flexible patterns based on content. When tracing a spiral, for example, we don't jump across the image line by line. Instead, we follow the shape.
Deepseek OCR 2 tries to mimic that approach. The new DeepEncoder V2 first processes visual tokens based on their content, rearranging them according to context before a language model interprets what's there. The thinking behind it: two processing steps working in sequence could enable genuine understanding of two-dimensional image content.
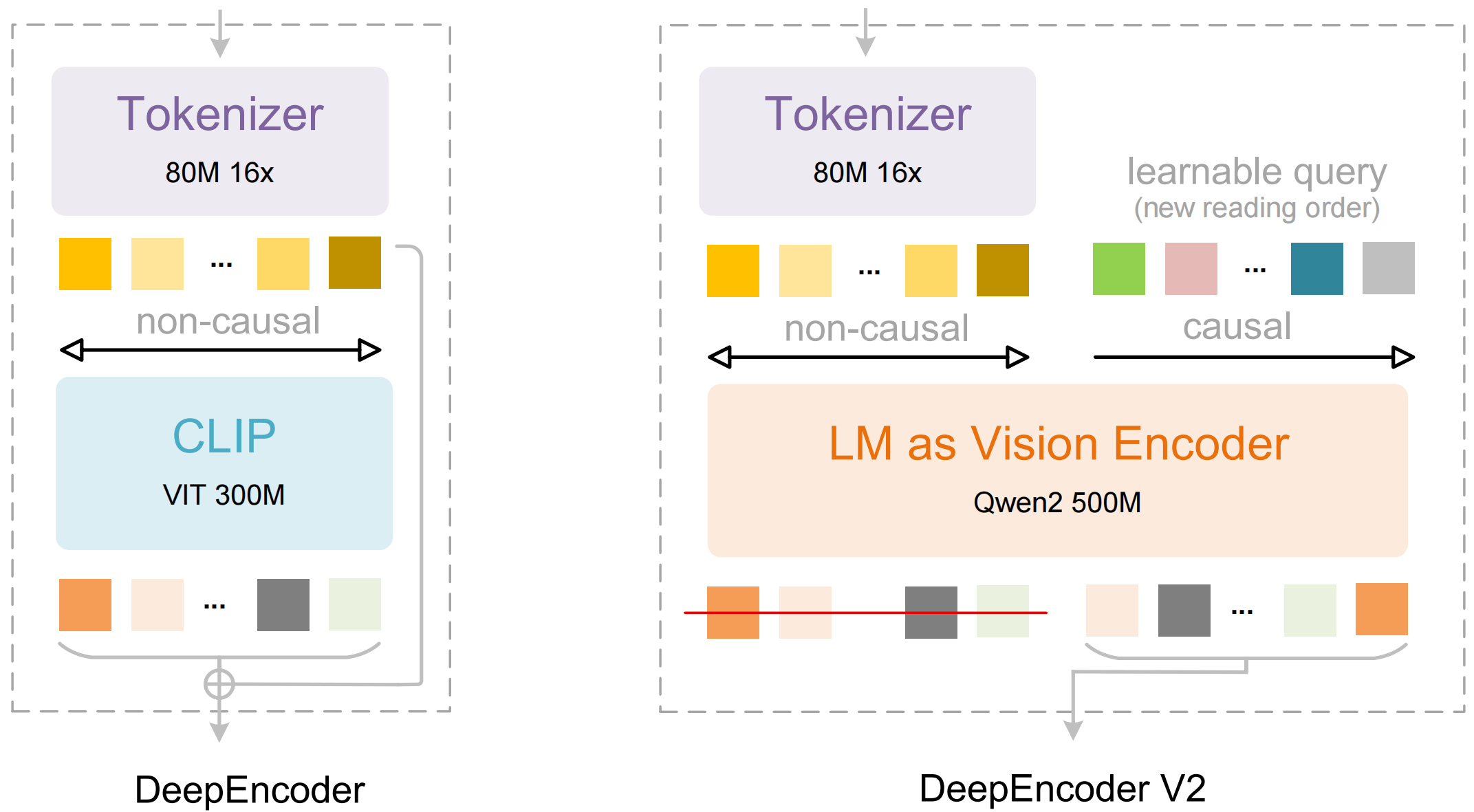
Language model replaces traditional vision encoder
At its core, DeepEncoder V2 swaps out the typical CLIP component for a compact language model architecture based on Alibaba's Qwen2 0.5B. The researchers introduced what they call causal flow tokens. These are learnable query tokens that attach to visual tokens and can access all image information along with previous queries.
According to the paper, this creates a two-stage process. First, the encoder reorganizes visual information based on content. Then the downstream LLM decoder reasons over the already sorted sequence. Only the rearranged causal flow tokens get passed to the decoder, not the original visual tokens.
Fewer tokens, better results
Deepseek OCR 2 uses between 256 and 1,120 visual tokens depending on the image. Comparable models often need more than 6,000 or 7,000 tokens. On OmniDocBench v1.5, a document processing benchmark covering 1,355 pages across nine categories, the model scored 91.09 percent overall, according to the researchers.
That's a 3.73 percentage point improvement over its predecessor, Deepseek OCR. The gains are especially clear in recognizing correct reading order. For document parsing, Deepseek OCR 2 also outperformed Gemini 3 Pro with a comparable token budget.
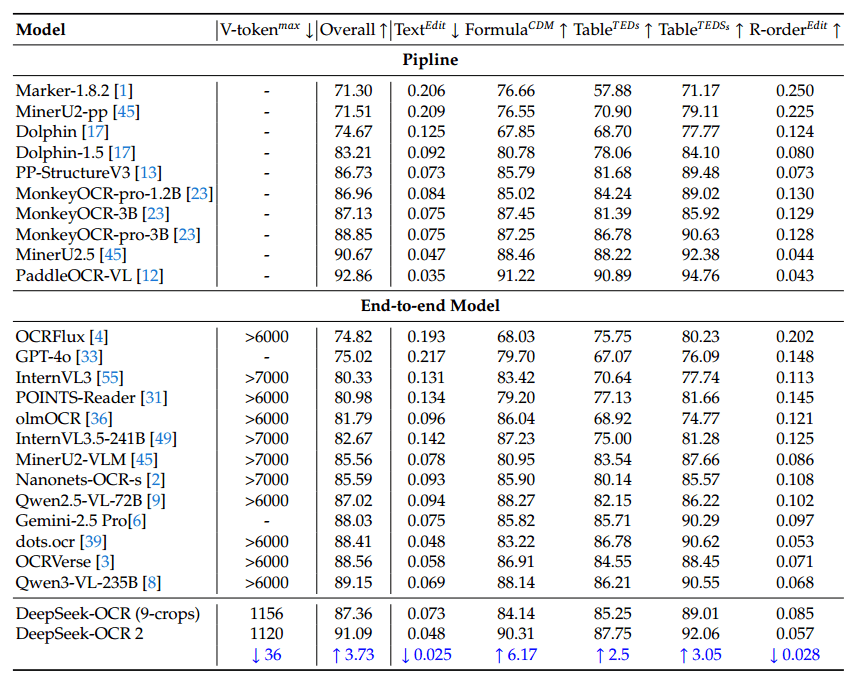
In practical use, the repetition rate has also improved. This measures how often the model falls into redundant text loops. When serving as an OCR backend for Deepseek's language models, this rate dropped from 6.25 to 4.17 percent. For batch processing PDFs into training data, it fell from 3.69 to 2.88 percent.
The model does have weak spots, though. It performs worse than its predecessor on newspapers, for example. The researchers point to two factors: the lower token limit could cause problems for text-heavy newspaper pages, and training data included only 250,000 newspaper pages, which wasn't enough material in that category.
A step toward unified multimodal processing
The researchers see DeepEncoder V2 as progress toward standardized multimodal processing. In the future, the encoder architecture could evolve to handle text, speech, and images with the same basic framework, adapting only the query tokens based on modality. According to the paper, this approach could eventually lead to genuine understanding of two-dimensional content.
Code and model weights are publicly available on GitHub and Hugging Face.
Deepseek released the first generation of Deepseek OCR just last October. That system processes text documents as images and cuts memory requirements by a factor of ten. As a result, language models can retain significantly more context, which is useful for long chat histories or extensive documents. According to Deepseek, the system can handle up to 33 million pages per day and works especially well for generating large training datasets.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now