Deepseek's hybrid reasoning model V3.1-Terminus delivers higher scores on tool-based agent tasks
Deepseek has rolled out V3.1-Terminus, an improved version of its hybrid AI model Deepseek-V3.1.
V3.1-Terminus now does a better job distinguishing between Chinese and English, and eliminates errors like random special characters. Deepseek has also tweaked its built-in agents, including code and search agents, for more reliable results, the company says.
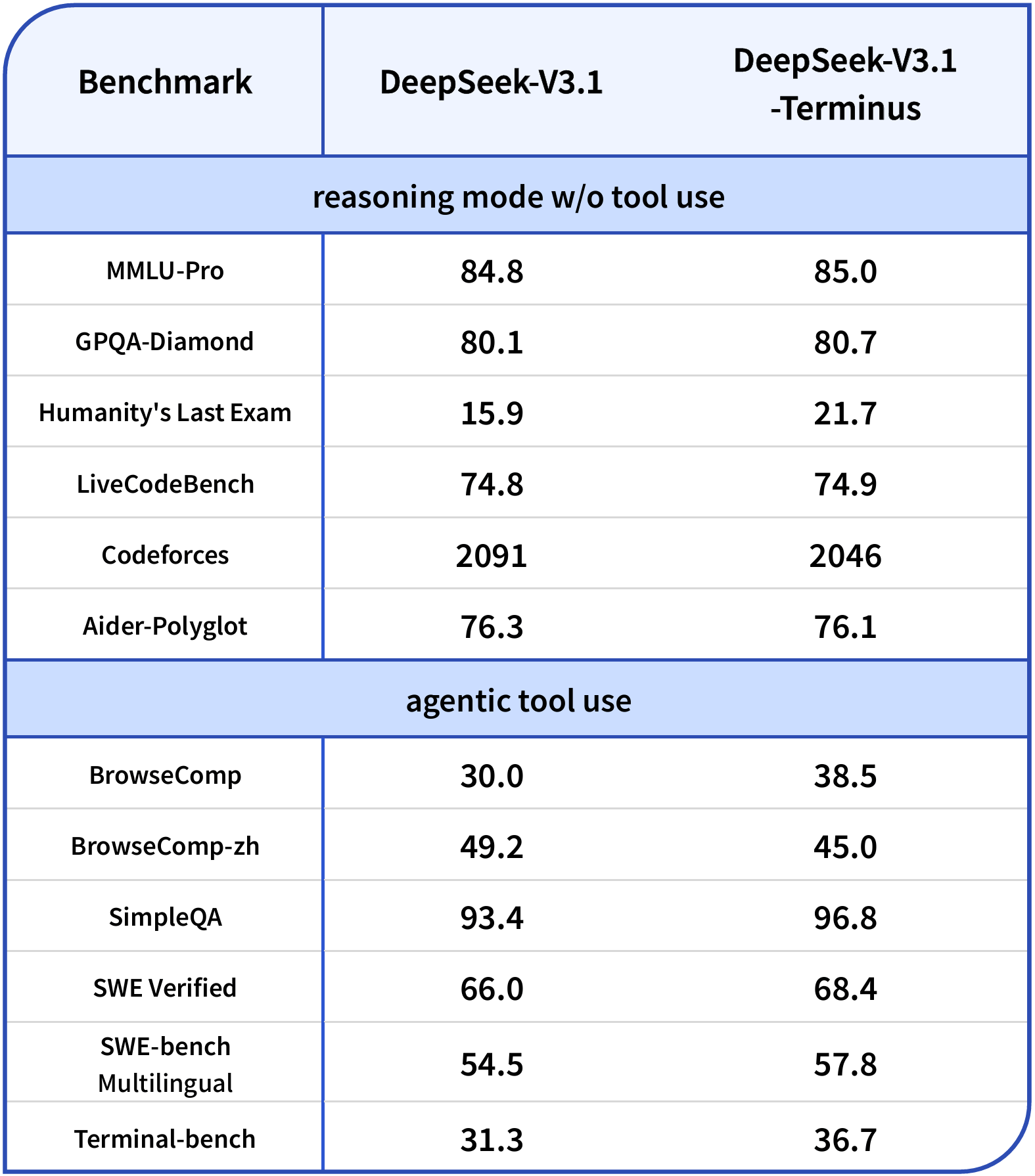
Benchmark results show the biggest gains in tasks that require tool use. On the BrowseComp benchmark, V3.1-Terminus jumps from 30.0 to 38.5 points. On Terminal-bench, it goes from 31.3 to 36.7.
Deepseek's chart also indicates a tradeoff: performance improves on the English-language BrowseComp, while BrowseComp-ZH on the Chinese web slips slightly. For pure reasoning tasks without tool use, the improvements are more modest.
The model is available through app, web, and API. Open-source weights can be found on Hugging Face under an MIT license.
Two thinking modes and aggressive pricing
V3.1-Terminus builds on Deepseek-V3.1, first released in August, which introduced two separate modes: a "thinking" mode (Deepseek-reasoner) for complex, tool-based tasks, and a "non-thinking" mode (Deepseek-chat) for straightforward conversations. Both modes support a context window of up to 128,000 tokens.
The model was trained on an additional 840 billion tokens, using a new tokenizer and updated prompt templates. Deepseek-V3.1 has already posted strong results against hybrid models from OpenAI and Anthropic, and outperformed Deepseek's own pure reasoning model R1.
Deepseek has kept its aggressive pricing from the initial release: output tokens still cost $1.68 per million, well below GPT-5 ($10.00) and Claude Opus 4.1 (up to $75.00). The API charges $0.07 per million tokens for cache hits and $0.56 for cache misses.
Like other Chinese AI models, Deepseek's latest release is subject to state censorship, making it a propaganda tool for the Chinese government on political topics. The Trump administration has proposed similar restrictions for US-based models. According to a recent Deepseek code review, these interventions can directly impact model performance.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.