Distributed machine learning can improve AI data protection

AI systems are trained with a wide range of data. Often, this includes personal information. Distributed machine learning can improve data protection in AI development, as the data being used is processed on users' devices rather than on a central server. However, there are also more potential entry points for attackers. The German platform "Learning Systems" (learning systems) provides an overview in its current issue of "AI at a glance".
In distributed machine learning, each end device accesses the current model and trains it locally with its own data set. Potential personal data therefore does not need to be processed through a central server.
To update and improve the ML model, not the actual data but only the training results (called weights) are shared with other end devices. There are three technical approaches to distributed machine learning.
Split Learning
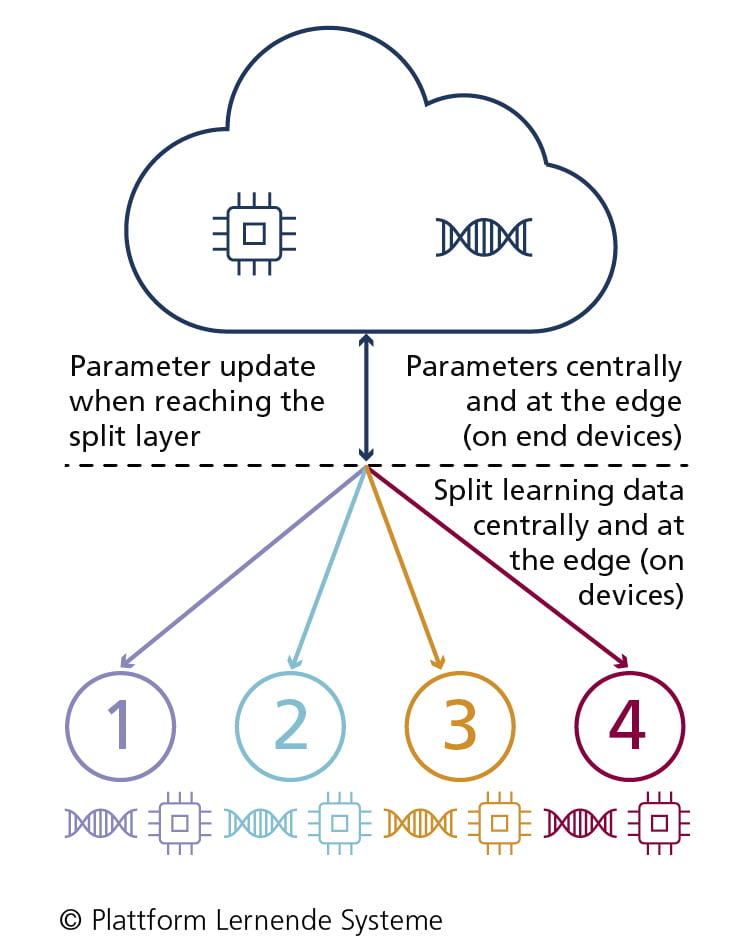
In split learning, the AI model is trained on endpoints and the server.
- ML model is split into different sub-models (so-called links) and trained both on end devices (clients) and on the server without sharing raw data (efficient distribution of computational load)
- Iterative training process: at the split point of the ML model (so-called split layer) end devices and servers swap only results (weights) of the trained ML model section (instead of raw data) and continue training with these results on their own data set (lower communication costs).
- Iterations end when convergence between the ML models of the end devices and the server is achieved.
Federated learning
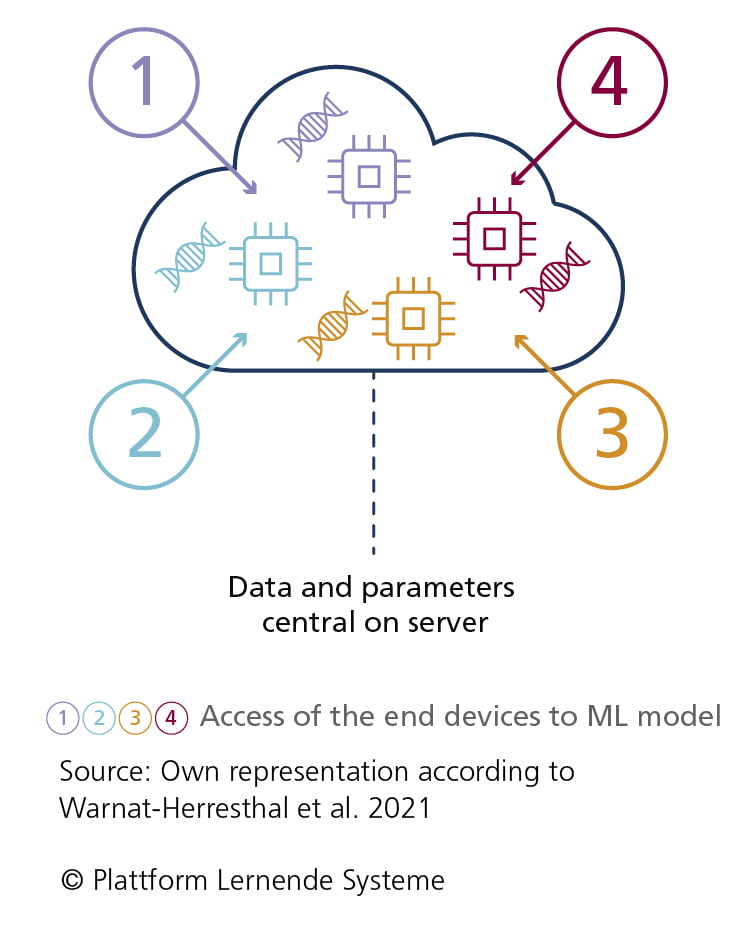
In federated learning, a central server acts as an aggregation instance for weights.
- End devices download parameters of the ML model from the server
- ML model is trained by end devices with local data set
- End devices only send weights to the server; local data set remains with the end device
- No training takes place on the server, only the composition of the weights
for central updating of the ML model (inference) - Server provides parameters of the improved, because synchronized, ML model for end devices for new training
- The process can be repeated as many times as required, with the distributed ML model constantly optimizing itself further
Swarm Learning
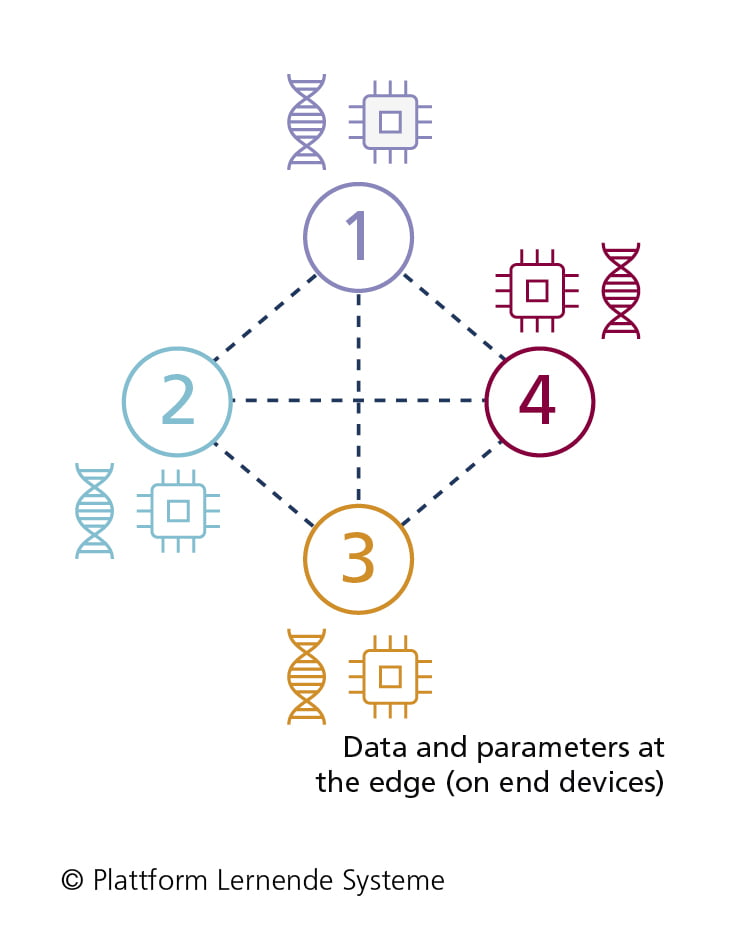
In swarm learning, an AI model is trained on distributed devices without a central aggregation instance.
- Parameters of the ML model are stored in an access-restricted blockchain instead of on a central server
- No coordination instance, but a central instance for the pre-authorization of end devices necessary for access to blockchain
- End devices load parameters of the ML model from the blockchain and can train it with a local dataset
- After training, only the adjusted weights are stored in the blockchain
- Adjusted weights and parameters of the ML model can be read by end devices and assembled locally to form the overall model
Application examples for distributed machine learning
One potential application for split learning is image recognition for autonomous driving. The continuous improvement of a basic image recognition model could be distributed among many vehicles, each of which uses its sensor data to refine the model. They then provide the locally trained parameters to the basic model on the central server for further training. In this way, the privacy-relevant route is processed entirely locally.
Another example is the local training of AI models for smartphone autocompletion and correction. Through federated learning, only the weights of the model are shared with the central server. Texts written with the smartphone, which can give clues about life situations or even reveal company secrets, thus remain on the device.
Swarm learning could help diagnose diseases without privacy concerns. The diagnostic model is distributed on the blockchain to various clinics licensed through health insurance companies. The parameters of the central model are retrieved by the clinics, locally merged into an overall model, and trained with local health data. The parameters of the updated model are then synchronized back to the blockchain. Medically sensitive, personal information is not transferred.
For a detailed look at distributed machine learning, see "AI Compact - Distributed Machine Learning".
Advantages and disadvantages of distributed machine learning
"Distributed Machine Learning opens up new possibilities for effective and scalable use of data without having to share it. This enables many useful applications with sensitive data possible in the first place," says Ahmad-Reza Sadeghi, professor of computer science at Darmstadt University of Technology and member of the IT Security and Privacy working group of the Plattform Lernende Systeme.
But there are also challenges: Distributing data and training processes across many endpoints creates new gateways for attackers. In addition, distributed machine learning requires an Internet connection for parameter exchange, which can lead to instabilities.
Model updates allow conclusions to be drawn about personal data. In addition, data of individual persons can be identified in the training dataset. The following graphic provides an overview of the advantages and disadvantages.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.