
A new project aims to unite all European languages in one model. EuroLingua is now getting the computing power it needs on a supercomputer in Barcelona, according to Fraunhofer IAIS (Institute for Intelligent Analysis and Information Systems) and AI Sweden.
The two organizations have gotten computing time on the new MareNostrum 5 supercomputer at the Barcelona Supercomputing Center from the European High-Performance Computing Joint Undertaking (EuroHPC JU). This is one of the largest allocations ever given for developing large European language models on the EuroHPC infrastructure.
EU AI models with up to 180 billion parameters
Starting in late May 2024, the partners will begin training the first multilingual models as part of the year-long "EuroLingua-GPT" project.
With an allocation of 8.8 million GPU hours on Nvidia's H100 chips, the partners will be able to train small models ranging from 7 to 34 billion parameters and large models with up to 180 billion parameters from scratch. The first models will be made available as open source in the coming months.
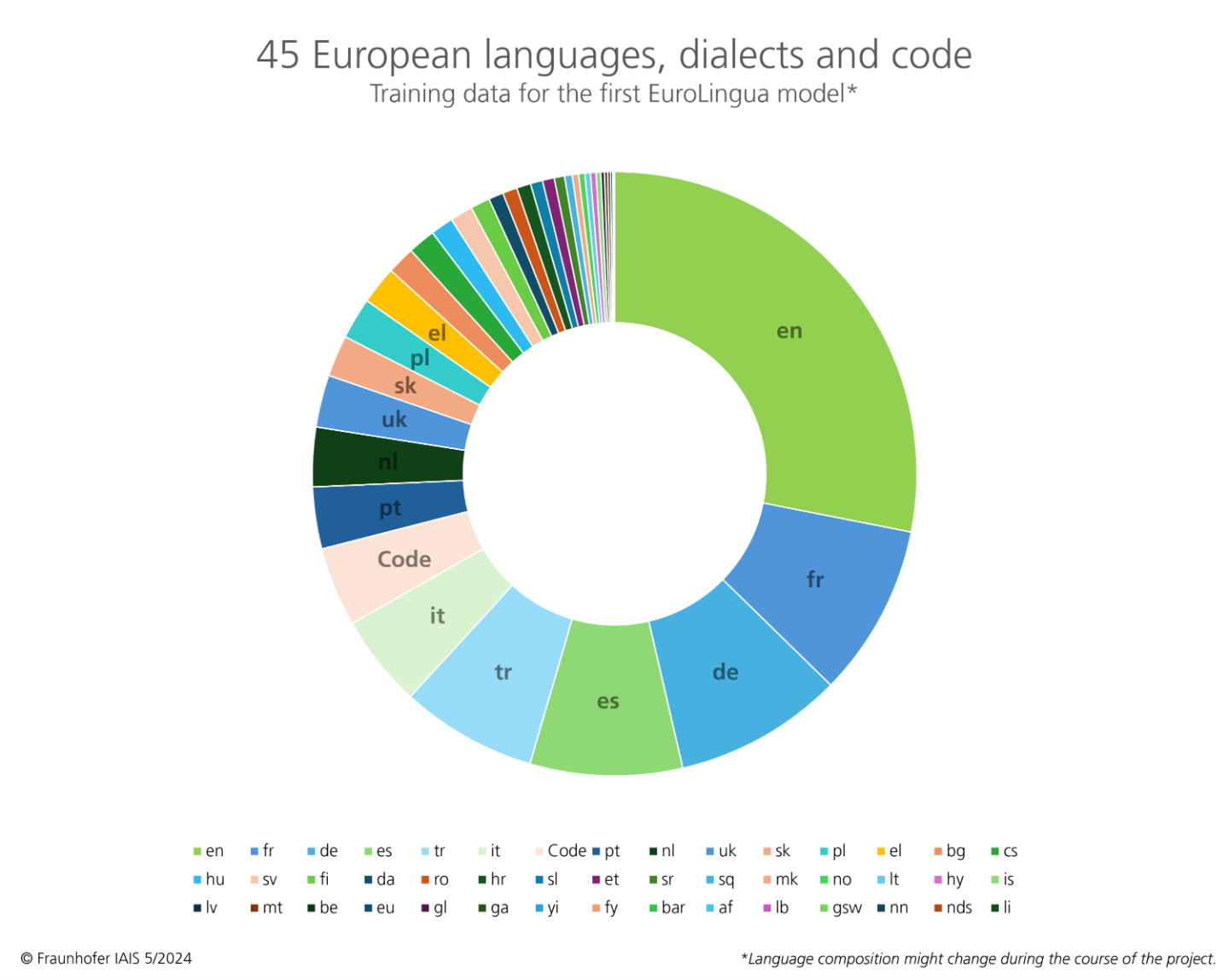
The EuroLingua models are based on a training dataset of 45 European languages, dialects, and code, including the 24 official European languages. This puts a big focus on European languages and values, as multilingual AI language models are still rare.
These computing capacities are a milestone for Germany and Europe. The models trained with it will massively accelerate the use of generative AI in companies and give both business and science a boost – GenAI 'made in Europe' is thus becoming a reality-
Joachim Köhler, Head of the NetMedia department at Fraunhofer IAIS
Fraunhofer IAIS and AI Sweden are pooling their knowledge for this project. Fraunhofer IAIS is leading the OpenGPT-X project funded by the German Federal Ministry of Economics, which is also developing large European multilingual open-source models. The NLU (Natural Language Understanding) group at AI Sweden has developed the GPT-SW3 LLM for the Scandinavian languages.
Big generalists and small experts
EuroLingua-GPT is one of three major ongoing EU projects on language models in which Fraunhofer IAIS and AI Sweden are involved, along with TrustLLM and Deploy AI.
The models developed on the EuroHPC setup are meant to help research and science in general, and they'll later be specialized for productive use in companies or public offices through joint transfer projects.
In addition to Sweden, Finland is also working on open-source language models for Europe. One example is Poro by Silo AI. However, a strong multilingual model is still a long way off.

French AI startup Mistral has already shown great progress with Mixtral, but it only outperforms other open models in European benchmarks in French, Italian, German and Spanish. So there are still plenty of languages to go.




