
- Meta AI has disabled the demo feature of the Galactica website. This could be a reaction to criticism from scientists.
The Galactica large language model (LLM) is being trained with millions of pieces of academic content. It is designed to help the research community better manage the "explosion of information."
Galactica was developed by Meta AI in collaboration with Papers with Code. The team identified information overload as a major obstacle to scientific progress. "Researchers are buried under a mass of papers, increasingly unable to distinguish between the meaningful and the inconsequential."
Galactica is designed to help sort through scientific information. It has been trained with 48 million papers, textbooks and lecture notes, millions of compounds and proteins, scientific websites, encyclopedias and more from the "NatureBook" dataset.
Language models as a new research interface
Galactica can store, combine, and reason about scientific content, the research team says. In benchmarks such as the mathematical MMLU, it far outperforms larger language models such as Chinchilla (41.3% to 35.7%) or PaLM 540B (20.4% to 8.8%).
For technical knowledge tests such as LaTeX equations, Galactica outperforms GPT-3 by 68.2% vs. 49.0%. Galactica also achieves new records (77.6% and 52.9%) in answering technical questions from biology and medicine (PubMedQA and MedMCQA).
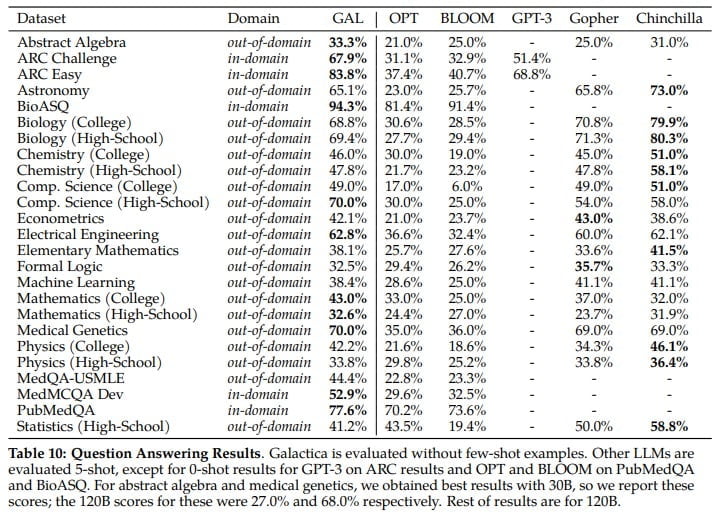
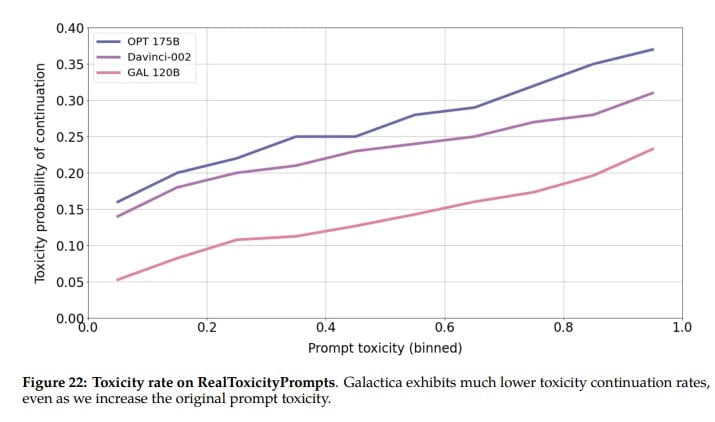
In addition, Galactica beats the large open-source language models Bloom and OPT-175B in the "BIG-Bench"-Benchmark for general language tasks, although it was not optimized for them. According to the team, the generated texts are significantly less toxic compared to other open-source language models.
We suspect this result reflects the higher-quality of the Galactica corpus, stemming from the fact it is curated and also primarily academic text. Previous open LLM efforts likely overfocused on scale goals and underfocused on data filtering.
From the paper
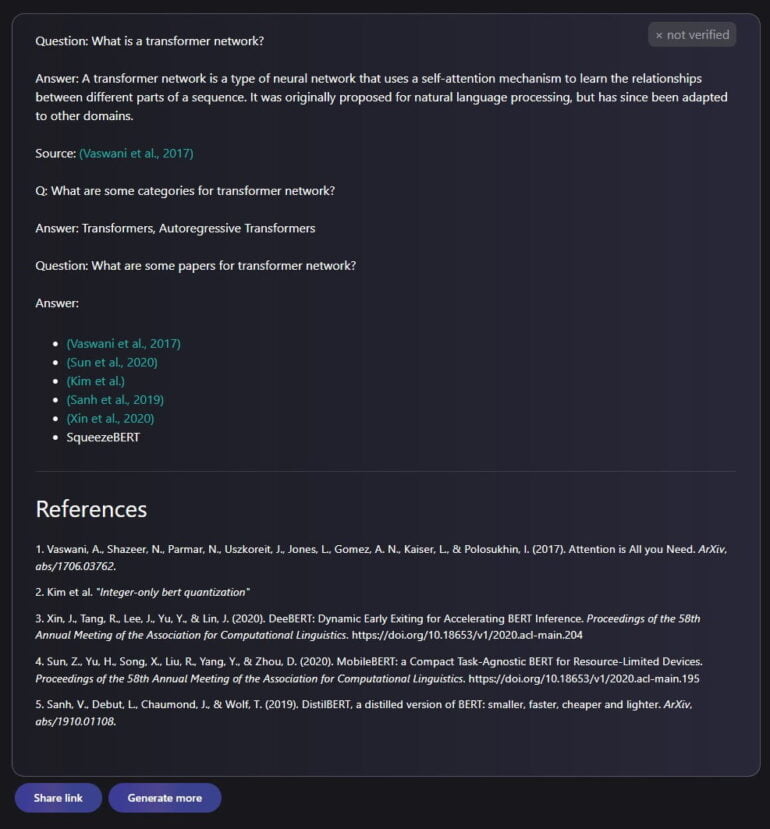
As specific application scenarios, the Galactica team mentions the creation of literature reviews, wiki articles, or lecture notes on scientific topics or answering scientific questions including citations.
When asked what a "Transformer Network" is, Galactica generates the following short explanation with literature references including links to papers.
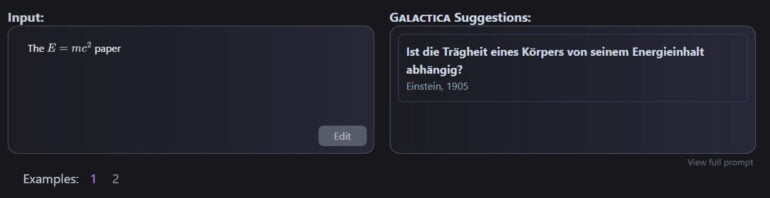
The model also offers a kind of paper search, where you can describe the content of a paper and receive a possibly matching one. It can search for specific mathematical formulas or describe them in natural language or suggest citations. For the latter function, however, the accuracy is only between 36.6 and 69.1 percent depending on the test data set and shows a bias in favor of well-known papers.

Much room for improvement
"We believe these results demonstrate the potential for language models as a new interface for science," the researchers write. Galactica, they say, is just the first step on this journey.
In its paper, the team describes numerous opportunities for improvement, including the use of more and non-publicly available academic sources and multimodal training with data outside of text, such as protein models.
Demo video for Galactica. | Video: Galactica / Meta AI
"Taken together, we feel there is a strong potential for language models to take on knowledge tasks that are currently human specialisms," the researchers write. They describe their ultimate vision as a single neural network for all scientific tasks, acting as the "next interface" for accessing knowledge.
In total, the team trained five Galactica models between 125 million and 120 billion parameters. Galactica's performance increases smoothly with scale, according to the team. All models are open source and freely available on Github.




