Google DeepMind launches new AI fact-checking benchmark with Gemini in the lead
Google DeepMind has introduced FACTS Grounding, a new benchmark that tests AI models' ability to provide accurate, document-based answers.
The benchmark uses 1,719 selected examples where AI models must generate detailed responses based on provided documents. The benchmark's unique feature is its evaluation method: three leading AI models—Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet—serve as judges.
These models evaluate responses on two key criteria: whether the answer adequately addresses the query, and whether it's factually correct and fully supported by the source document.
The test documents span various fields, including finance, technology, retail, medicine, and law. These documents can be up to 32,000 tokens (approximately 20,000 words) in length. The tasks include summaries, question-answering, and rephrasing exercises. Human evaluators created and verified these tasks to ensure they don't require creative responses, expert knowledge, or mathematical understanding.
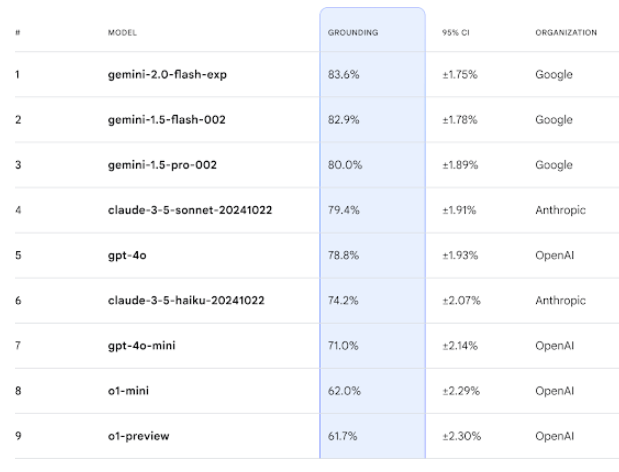
To calculate final scores, the benchmark combines results from different scoring models for each answer. The overall task score represents the average of all scoring model results across all examples. Google DeepMind hosts a FACTS Leaderboard on Kaggle.
Preventing gaming the system
Google DeepMind says it will continue developing the benchmark. "Factuality and grounding are among the key factors that will shape the future success and usefulness of LLMs and broader AI systems," the company writes.
To protect against manipulation, Google DeepMind split the benchmark into two parts: 860 public examples available now and 859 examples kept private. The final score combines results from both sets.
Google DeepMind acknowledges that while large language models are changing how people access information, their factual accuracy control remains imperfect. Complex inputs can still lead to hallucinations, potentially undermining trust in LLMs and limiting their practical applications.
FACTS Grounding takes a different approach from other tests like OpenAI's SimpleQA. While SimpleQA tests models with 4,326 knowledge questions they must answer from training data, FACTS Grounding evaluates how well models process new information from provided documents.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.