Google unifies text, image, video, and audio in a single vector space with Gemini Embedding 2

Key Points
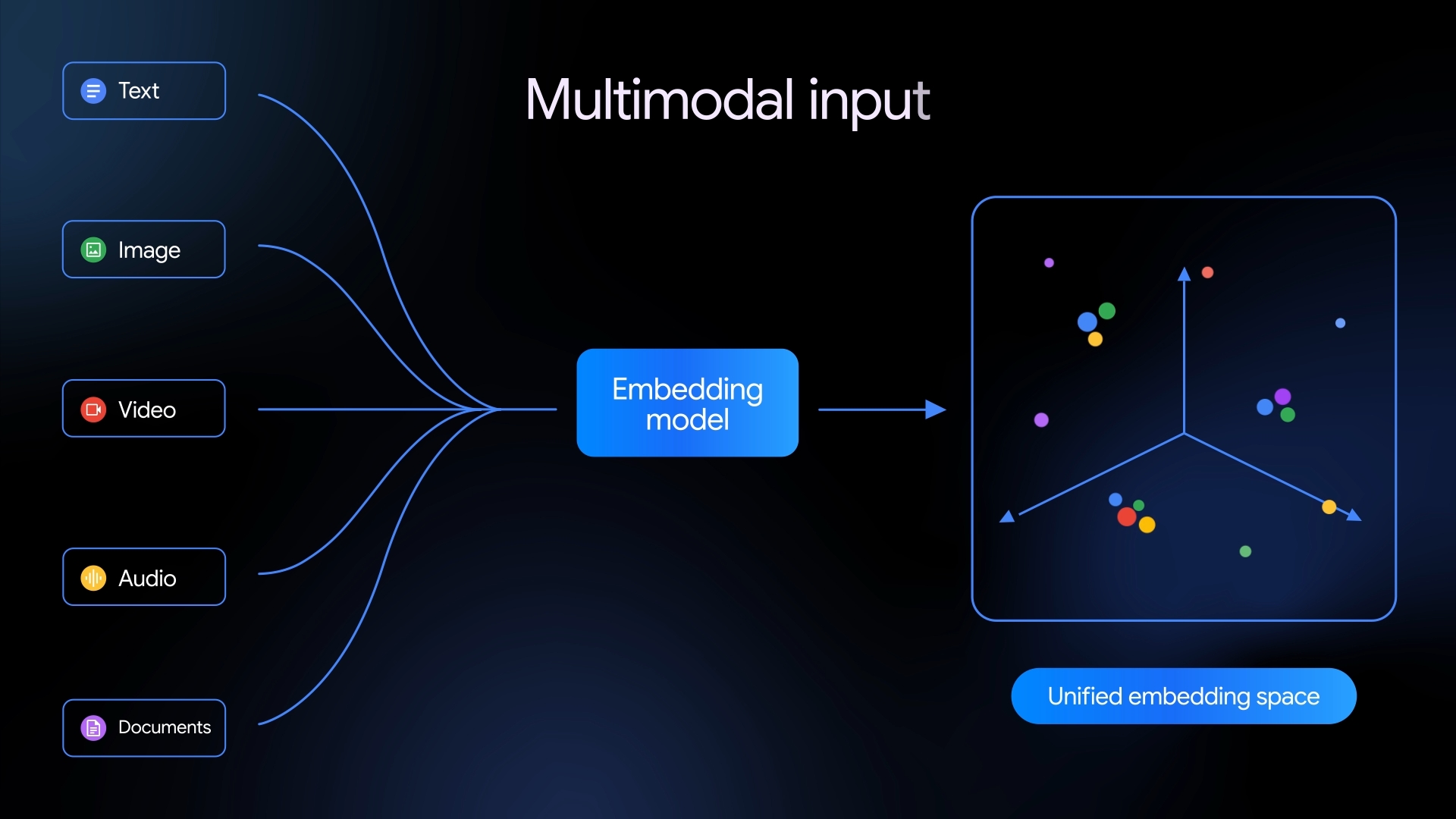
- Google has released Gemini Embedding 2, its first native multimodal embedding model. It maps text, images, videos, audio, and PDFs into a shared vector space, making them directly comparable.
- The model handles audio natively without needing a transcription step and lets users combine multiple modalities in a single request. It also quadruples the token limit to 8,192.
- Google says Gemini Embedding 2 beats out competitors like Amazon's Nova 2 and Voyage Multimodal 3.5 in nearly every benchmark category, with especially strong results on text-to-video tasks.
Google's first native multimodal embedding model maps text, images, video, audio, and documents into one shared semantic space, potentially simplifying complex AI pipelines.
Back in July 2025, Google shipped gemini-embedding-001, a text-only embedding model supporting over 100 languages that landed a top spot on the MTEB Multilingual Leaderboard. With Gemini Embedding 2, the company is making a much bigger move: the new model still builds on the Gemini architecture, but now also maps images, video, audio, and PDF documents into the same vector space as text.
Embeddings are numerical representations of data that capture its meaning. They're the backbone of applications like semantic search, retrieval augmented generation (RAG), sentiment analysis, and data clustering. A shared embedding space makes it possible to compare different media types directly, without running them through separate models or adding extra steps.
Native audio processing cuts out the transcription middleman
Google says Gemini Embedding 2 supports up to 8,192 input tokens for text, four times the 2,048-token limit of its predecessor. It can handle up to six images per request in PNG and JPEG formats. Videos can run up to 120 seconds, and PDF documents can be up to six pages long.
The audio side is worth noting. The model processes audio natively without converting it to text first. Most previous approaches rely on a speech-to-text step in between, which tends to lose information along the way. Gemini Embedding 2 skips that entirely.
There's also what Google calls "interleaved input:" developers can mix multiple modalities in a single request, like pairing an image with a text description. Google says this helps the model pick up on relationships between different media types better than embedding each one on its own.
Like its predecessor, Gemini Embedding 2 uses Matryoshka Representation Learning (MRL). The technique layers information so output dimensions can be scaled down dynamically, like a Matryoshka doll where smaller representations nest inside larger ones.
The default dimension is 3,072, with Google recommending 1,536 and 768 as useful alternatives. This lets developers trade off between maximum quality and lower storage costs depending on their use case. Google says the model supports semantic capture in over 100 languages.
Benchmarks show a clear lead across every modality tested
Google backs up its performance claims with benchmark comparisons against Amazon's Nova 2 Multimodal Embeddings, Voyage Multimodal 3.5, and its own earlier models. According to the published numbers, the new model comes out on top in every category tested: text, images, video, and spoken language.
The gap is widest in text/video tasks: Gemini Embedding 2 hits up to 68.8 points, while Amazon Nova 2 lands at 60.3 and Voyage Multimodal 3.5 at 55.2. In text-image comparisons, Google also pulls ahead clearly with 93.4 versus Amazon's 84.0.

Gemini Embedding 2 is available through the Gemini API and Vertex AI. Google provides interactive Colab notebooks and supports integrations with popular frameworks and vector databases, including LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB, and Vector Search. The company also put out a lightweight demo for multimodal semantic search so developers can test the model's capabilities firsthand.
In late February, AI search engine Perplexity dropped two open-source embedding models under an MIT license. The models—pplx-embed-v1 and pplx-embed-context-v1—only handle text, but they focus on extreme memory efficiency and bidirectional text understanding.
On the MTEB retrieval benchmark, Perplexity's largest model reportedly matched Alibaba's Qwen3 embedding scores and outperformed Google's gemini-embedding-001 at the time, all while using significantly less memory.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now