Google's new AI referee Cappy brings out the best in large language models

Google Research has developed a new method called Cappy to improve the performance and efficiency of Large Language Models (LLMs). The lightweight, pre-trained scorer, with only 360 million parameters, allows LLMs to be adapted to specific tasks without fine-tuning.
Cappy is a scoring system that evaluates the quality of the answers generated by LLMs with comparatively little computational effort, and can therefore improve their performance, as Google engineers Yun Zhu and Lijuan Liu explain in a blog post.
The new method makes it possible to tailor LLMs to specific tasks without having to fine-tune model parameters. According to Google, this saves memory and processing power.
Cappy works as a kind of referee: it evaluates how well an LLM's answers match a specific question. Cappy assigns values between 0 and 1: the higher the value, the better the answer.
For example, if a user asks "What was the impact of the Industrial Revolution on society?" and the LLM generates several answers, Cappy can highlight the answer that covers the most important aspects, such as urbanization, the emergence of the working class, and social upheaval, and display it to the user.
Less relevant answers with low scores are hidden. In this way, Cappy ensures that the LLM provides the most accurate, relevant, and high-quality answers possible.
Cappy works either standalone in classification tasks or as an auxiliary component in multi-task LLMs to improve their performance.
Lean "scorer" optimizes LLM performance
To make these evaluations, Cappy is first trained on a large number of question-answer pairs. This way, the system learns to distinguish between good and bad answers. The existing language model RoBERTa serves as the basis for this pre-training process.
Cappy also works with LLMs that can only be used via APIs. In contrast to in-context learning approaches, where the information is provided directly in the prompt, Cappy is not limited by the input length and can include any number of training examples.
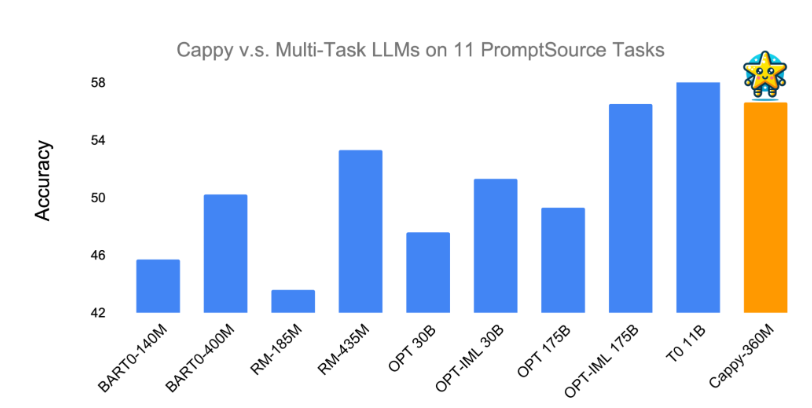
According to Google, Cappy has shown in tests that it can improve the performance of multitask LLMs. On eleven classification tasks from PromptSource, Cappy outperformed Meta's OPT-175B and OPT-IML-30B models and matched the accuracy of the best existing multitask LLMs (T0-11B and OPT-IML-175B).
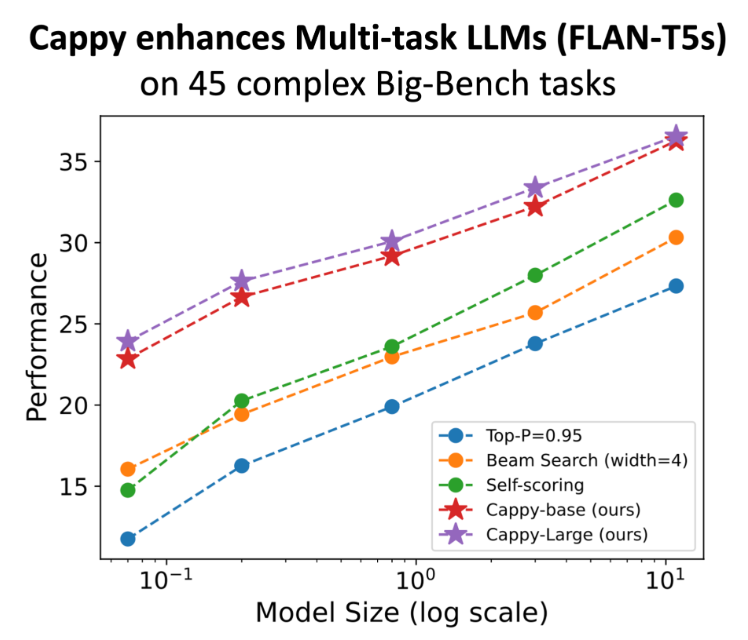
On 45 complex generation tasks from the BIG benchmark, which are considered challenging for many LLMs, Cappy was able to significantly improve the performance of the FLAN-T5 models. The combination of Cappy and FLAN-T5 consistently produced better results than the standard method of letting the language model evaluate its own responses.
Google researchers see Cappy as a promising approach to improving the performance and efficiency of AI language models. The process could make it possible to optimize LLMs for specific applications faster and with less effort.
This could make AI systems more flexible and widely applicable in the future, without the need for computationally intensive model fine-tuning. In the long term, Cappy could pave the way for a new generation of AI applications that are more efficient, flexible, and powerful than previous systems.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.