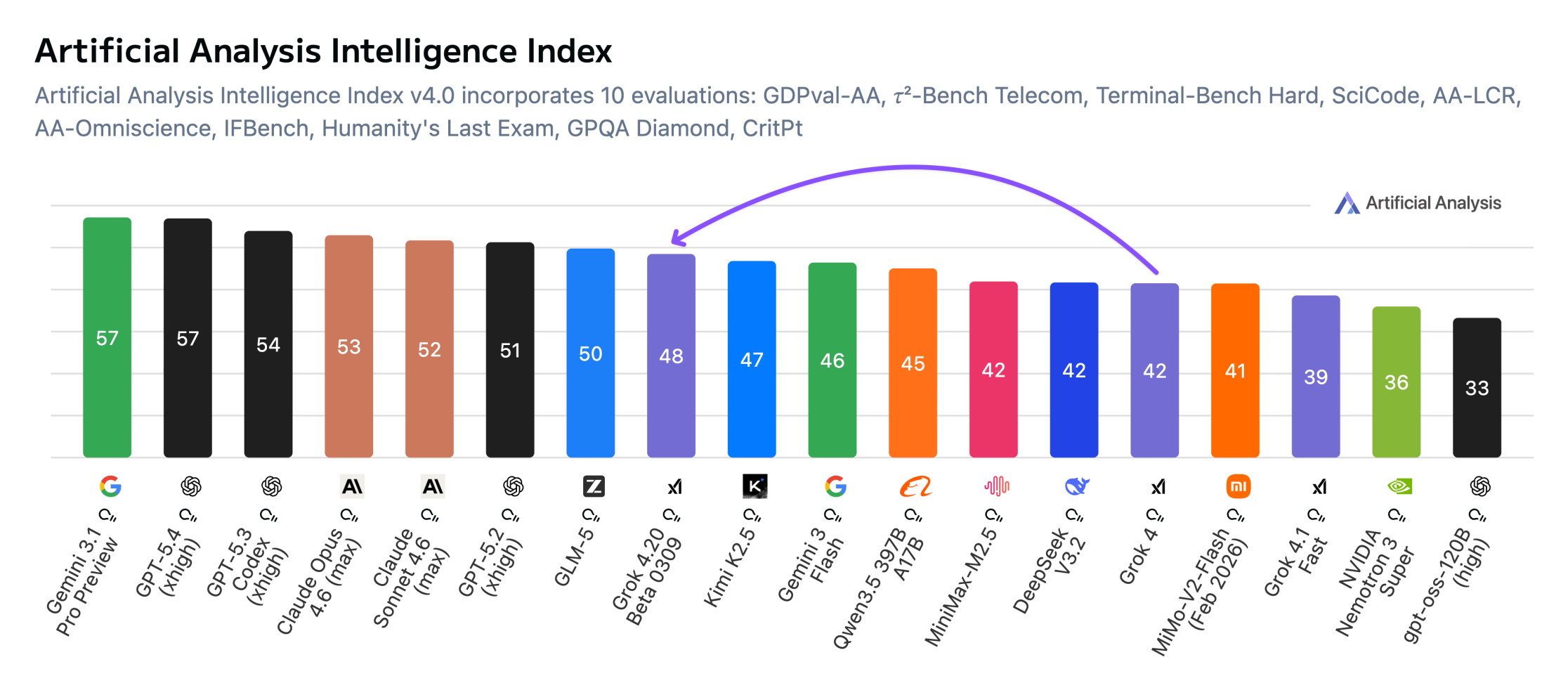
Grok 4.20 trails Gemini and GPT-5.4 by a wide margin but sets a new record for not hallucinating
xAI's Grok 4.20 can't keep up with the top AI models in benchmarks but hallucinates less than any other model tested. According to Artificial Analysis, Grok 4.20 Beta scores 48 on the Intelligence Index with reasoning enabled, well behind Gemini 3.1 Pro Preview and GPT-5.4 at 57, but still a 6-point improvement over Grok 4.
xAI shipped three API variants: with reasoning, without reasoning, and a multi-agent mode. The model supports a 2-million-token context window and costs 2 or 6 dollars per million tokens; cheaper than Grok 4 and competitively priced among Western models.
Where Grok 4.20 stands out, of all things, is factual reliability. On the AA Omniscience test, it hit a 78 percent non-hallucination rate, a record, according to Artificial Analysis. The test measures how often a model fabricates an answer instead of admitting it doesn't know, alongside factual recall. Grok 4.20 only got it wrong about one in five times when it didn't have the answer.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now