Know3D lets users control the hidden back side of 3D objects with text prompts
A research team taps into the knowledge of large language models to control the back side of objects via text during 3D generation from single images, addressing a fundamental problem in 3D generation.
When an AI model has to build a complete 3D object from a single photo, it's working with a major blind spot: the image only shows one side, so the model basically has to guess everything behind it. According to a new paper from a team at several Chinese universities, this regularly leads to physically implausible shapes or results that miss what the user was going for.
The issue comes down to data. Compared to the enormous image and text datasets floating around the internet, 3D training data is still hard to come by. The world knowledge 3D models absorb during training just isn't enough to reliably fill in what's hidden.
Know3D tackles this by pulling in the broad world knowledge of multimodal language models. Users can type out a text description of what should appear on the side of an object they can't see.
An image generator bridges the gap between language and 3D
The obvious move—feeding a language model's output straight into a 3D network—doesn't actually work, the researchers say. The representations are too abstract and don't carry enough spatial information to generate usable geometry.
So Know3D takes a detour, slotting an image generation model between the language model and the 3D generator to act as a translator. The setup uses Qwen2.5-VL as the language model, Qwen-Image-Edit for image generation, and Microsoft's Trellis.2 as the 3D generator.
The language model reads the text instruction and analyzes the input image. The image generator then turns that understanding into spatial-structural information that steers the 3D generator.
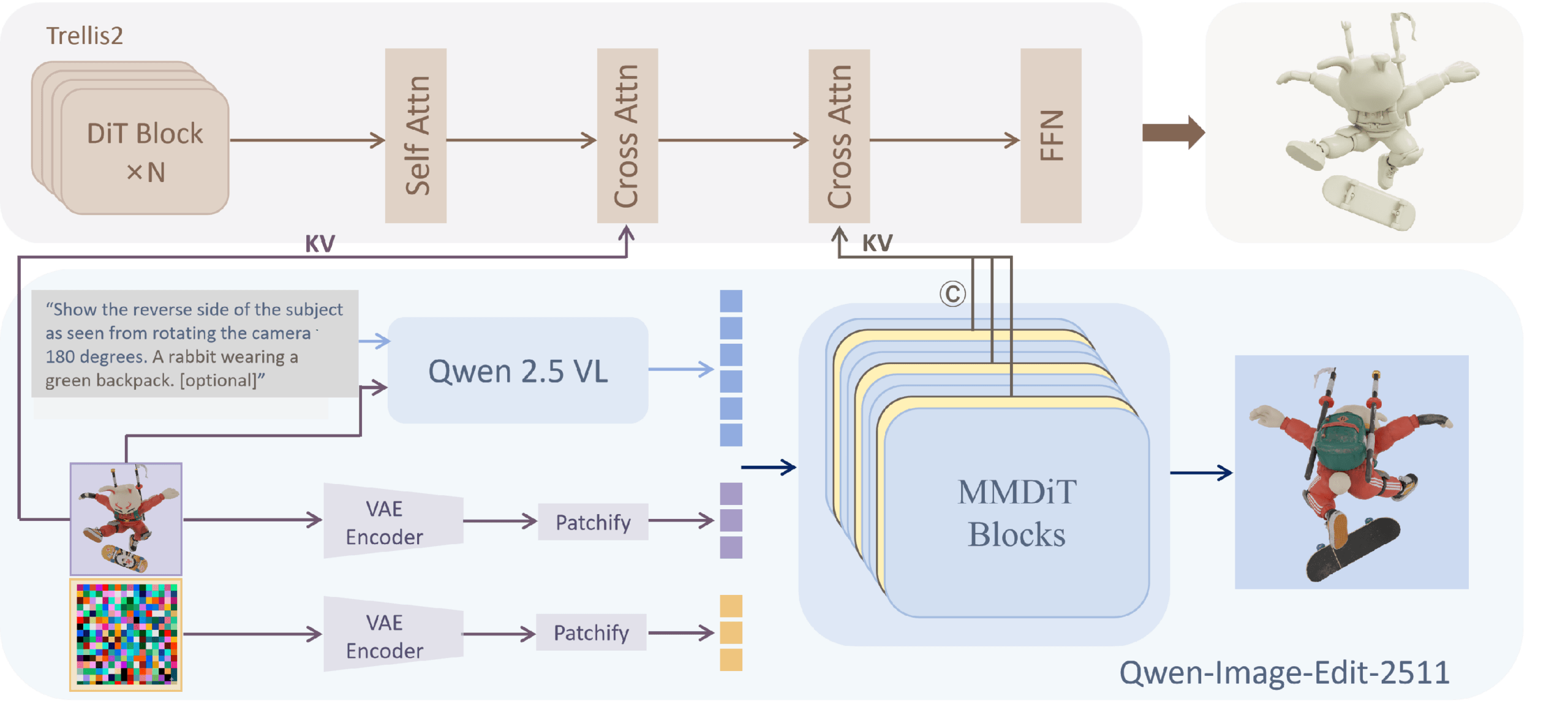
The trick is figuring out what information to pull from the image generator. The team tested three options: an internal image representation grabbed right before the final output, image features extracted from it via Meta's DINOv3, and the model's internal intermediate states during generation. The last option won by a clear margin—these intermediate states carry both semantic and spatial information without relying on pixel-level accuracy or mistakes in the final image.
Internal model states keep errors from spreading
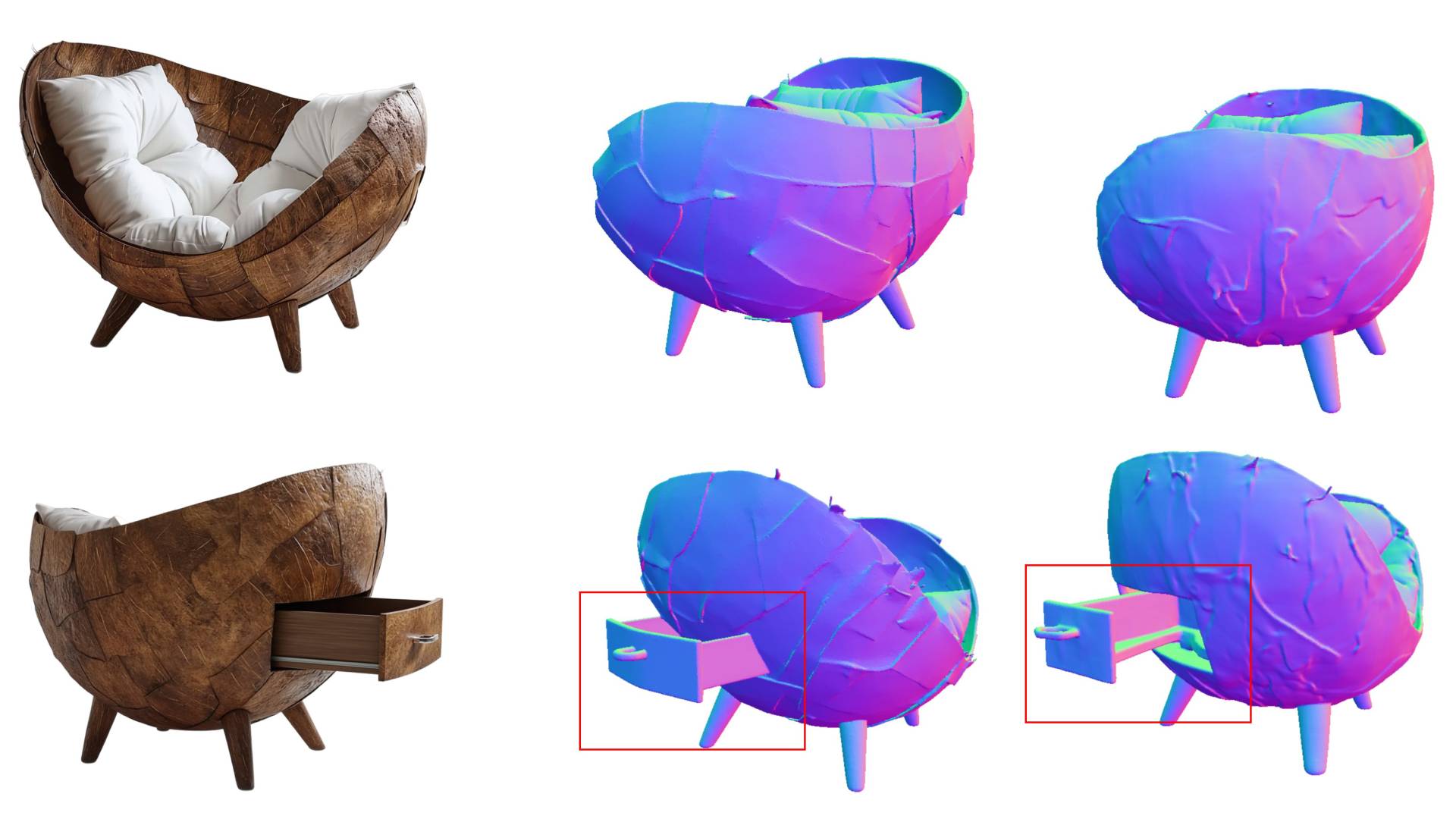
This matters in practice. If the image generator produces a bad rear view, like rendering a one-shoulder bag with two straps, image-based methods pass that mistake straight through to the 3D output.
The model's internal intermediate states are more forgiving: they seem to hold enough spatial and semantic information to still produce a solid 3D object. Even partway through processing, the model apparently builds a pretty reliable sense of structure and form.
The timing of when the team taps into those states matters, too. Go too early and the information is too focused on pixel details. Go too late and noise takes over. Their ablation studies showed that grabbing states at roughly the quarter mark of the process hit the sweet spot.
The main advantage of Know3D over existing methods is the degree of control it offers. The researchers demonstrate this with a coffee cup: the same input photo yields different but geometrically consistent back sides depending on the text instruction. The same principle applies to chairs, robots, and houses: the back adapts to match the description while the visible front remains unchanged.
Strong benchmark scores, but results hinge on the base model
Know3D posts the best scores for semantic match between input image and generated 3D object on HY3D-Bench, a benchmark built by the Hunyuan3D team. That holds up against both current single-image methods and an approach that feeds the generated rear view back in as a second input image. Know3D also beats the competition on geometric quality for the back sides, the researchers say.

How good the results are ultimately comes down to whether the underlying language model reads the text instructions correctly, the researchers say. If it misinterprets a prompt, the 3D output goes sideways too. So stronger multimodal models could cut down on this problem going forward.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.