LongCat-Image proves 6B parameters can beat bigger models with better data hygiene
Chinese tech company Meituan has released LongCat-Image, a new open-source image model that challenges the industry's "bigger is better" mindset. With just 6 billion parameters, the model reportedly beats significantly larger competitors in both photorealism and text rendering, thanks to strict data curation and a clever approach to handling text.
While rivals like Tencent and Alibaba keep building bigger models—Hunyuan3.0 packs up to 80 billion parameters—Meituan went the opposite direction. The team says brute-force scaling wastes hardware without actually making images look better. LongCat-Image instead uses an architecture similar to the popular Flux.1-dev, built on a hybrid Multimodal Diffusion Transformer (MM-DiT).

The system processes image and text data through two separate "attention paths" in the early layers before merging them later. This gives the text prompt tighter control over image generation without driving up the computational load.
Cleaning up training data fixes the "plastic" look
One of the biggest problems with current image AI, according to the researchers, is contaminated training data. When models learn from images that other AIs generated, they pick up a "plastic" or "greasy" texture. The model learns shortcuts instead of real-world complexity.
The team's fix was simple but aggressive: they scrubbed all AI-generated content from their dataset during pre-training and mid-training. Alibaba took a similar approach with Qwen-Image. Only during the final fine-tuning stage did they allow hand-picked, high-quality synthetic data back in.
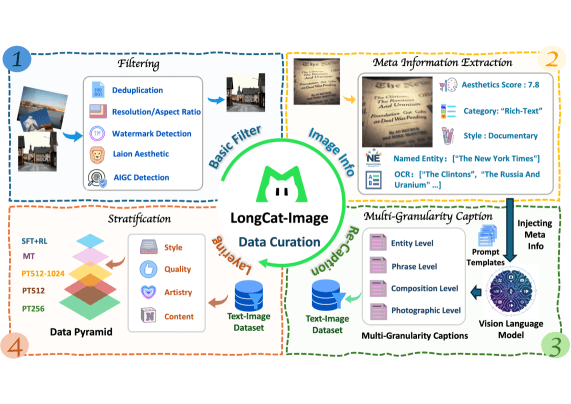
The developers also came up with a new reinforcement learning trick: a detection model that penalizes the generator whenever it spots AI artifacts. This pushes the model to create textures realistic enough to fool the detector.
The results speak for themselves. In benchmarks, the 6B model regularly outscores much larger models like Qwen-Image-20B and HunyuanImage-3.0. And because it's so efficient, it runs on far less VRAM - good news for anyone wanting to run it locally.
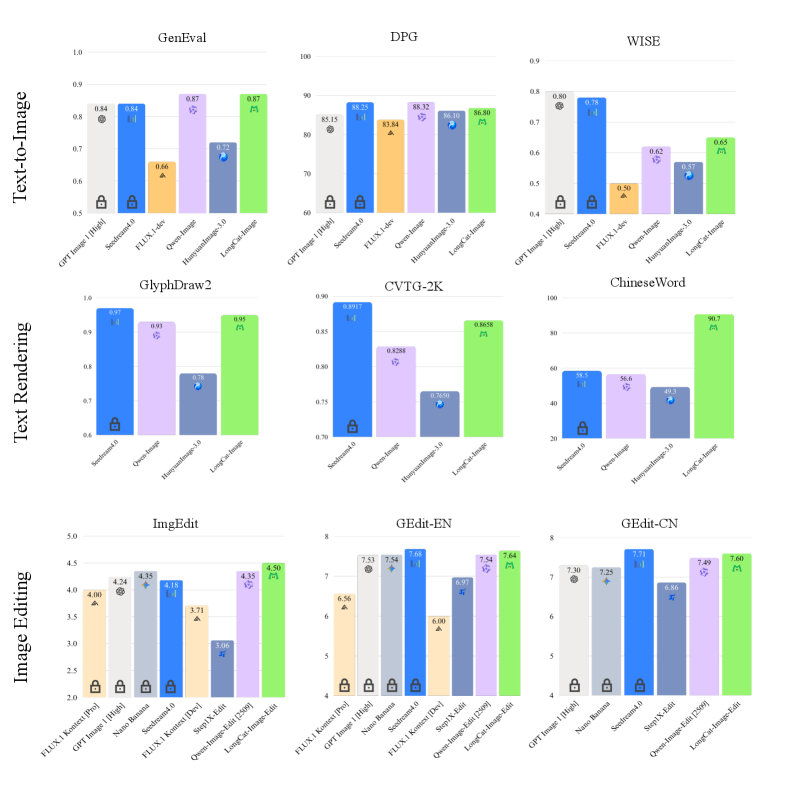
Letter-by-letter processing nails text in images
One of the model's best tricks is how it handles text inside images. Most models mess up spelling because they treat words as abstract tokens rather than individual letters. LongCat-Image takes a hybrid approach. It uses Qwen2.5-VL-7B to understand the overall prompt, but when it sees text in quotation marks, it switches to a character-level tokenizer. Instead of memorizing visual patterns for every possible word, the model builds text letter by letter.

Separate editing model keeps image quality intact
Rather than cramming everything into one model, the team built a standalone tool called LongCat-Image-Edit. They found that the synthetic data needed for editing training actually degraded the main model's photorealistic output.

The editing model starts from a "mid-training" checkpoint - a point where the system is still flexible enough to pick up new skills. By training it on editing tasks alongside generation, the model learns to follow instructions without forgetting what real images look like.

Meituan has posted the weights for both models on GitHub and Hugging Face, along with mid-training checkpoints and the complete training pipeline code.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.