Major news websites block AI crawlers specifically from OpenAI

A recent study by the Reuters Institute shows that a significant number of news websites are blocking AI crawlers from OpenAI and Google. These crawlers collect data from websites to train large language models (LLMs) and extract real-time information from websites.
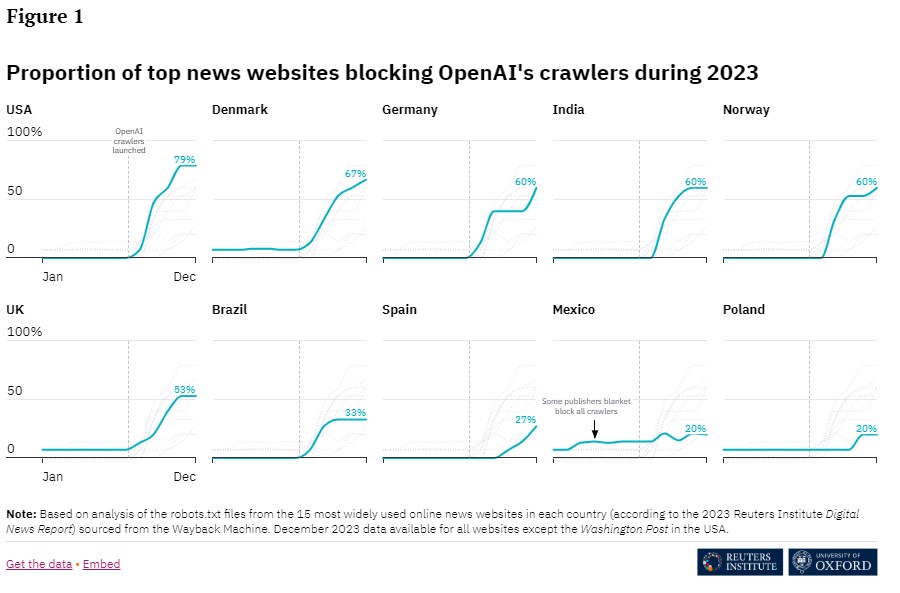
According to a study by the Reuters Institute, 48% of the most-used news sites in ten countries blocked OpenAI crawlers by the end of 2023. A smaller proportion, 24%, also blocked Google's AI crawler. In contrast, almost all sites that block Google's AI crawler also block the OpenAI crawler. Perhaps there is more reluctance to block the Google AI crawler because publishers are worried about the potential impact on search engine rankings.
The differences between countries are significant, with the percentage of news sites blocking OpenAI ranging from 79 percent in the U.S. to just 20 percent in Mexico and Poland. For Google, the numbers range from 60 percent in Germany to 7 percent in Poland and Spain.
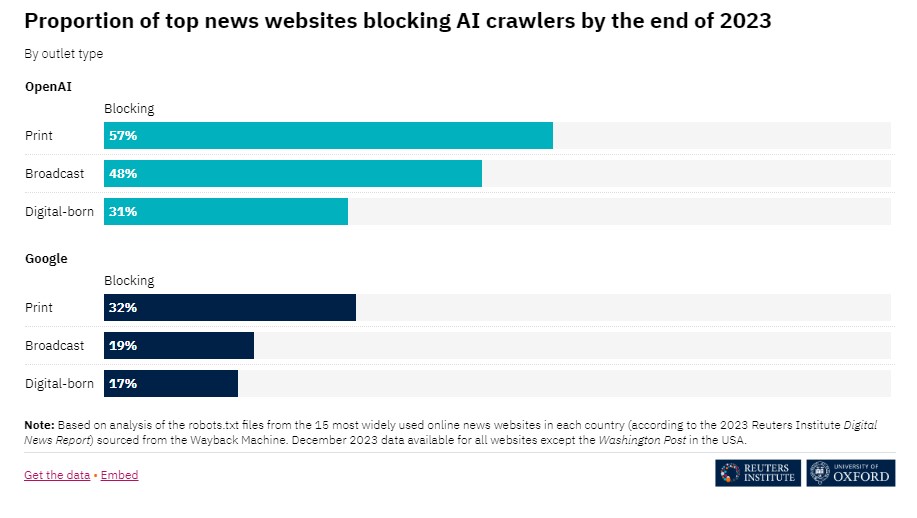
Print media sites are more likely to block crawlers than broadcast or digital publishers, which is surprising given that language models and chatbots pose the greatest economic risk to digital content. Publishers can use the robots.txt file on their sites to reject web crawlers.
There are two main reasons for blocking crawlers: The New York Times, for example, believes it should be compensated for allowing OpenAI and other AI companies to use its content to train AI models.
Others fear that chatbot platform providers will not link to publishers, or that these links will be displayed but not used. This would result in significant financial losses for publishers, who rely primarily on traffic to their sites.
Major AI companies such as OpenAI, Microsoft, and Google have recognized the problem, but have yet to address it. Currently, some publishers are said to be negotiating licensing deals with AI companies.
OpenAI has already announced a deal with Axel Springer and other publishers. This includes the use of content as training data and the provision of messages in chatbots.
AI crawlers, also known as "spiders" or "bots," systematically collect data from the Internet for various purposes. Search engines use the data collected by their web crawlers to index websites and quickly answer search queries.
AI companies like OpenAI use crawlers to collect data from the web and train their models. AI companies need vast amounts of data to operate efficiently, and the Web is a major source of high-quality textual and audiovisual data.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.