
Meta AI introduces Emu Video and Emu Edit for text-based image and video editing. The model is based on the Emu image model.
Meta's new video model can generate four-second videos from text and images. In terms of quality, the researchers say it is superior to commercial offerings such as Runway Gen-2 and Pika Labs. They make this claim based on human ratings of generated test videos.
Emu Video converts text to images and then to video
Emu Video is based on the Emu image model that Meta introduced at Connect 2023 this fall. Emu Video uses a standardized architecture for video generation tasks and processes text and image prompts or combined prompts.
The process is what makes Emu Video smart, and it consists of two steps: First, images are generated based on a text prompt, and then a video is generated based on both the text and the generated image.
This allows the model to retain the visual variety and style of the text-image model, which Meta AI says makes it easier to create videos and improves the quality of the output.
"The American flag waving during the moon landing with the camera panning." | Video: Meta AI
"a ship driving off the harbor." | Video: Meta AI
This "factorized" approach allows Meta to efficiently train video generation models and directly generate high-resolution videos. The model uses two diffusion models to generate 512x512 four-second videos at 16 frames per second. The researchers also experimented with videos up to eight seconds long, with good results.
To evaluate the quality of the generated videos, the team developed the JUICE (JUstify their choICE) human rating system. This approach requires raters to justify their decisions when comparing video quality using pre-formulated criteria, which is intended to increase the reliability of the rating process.

The quality factors are: Pixel Sharpness, Smooth Motion, Recognizable Objects/Scenes, Image Consistency, and Range of Motion. For prompt accuracy (text faithfulness), the reasons are spatial text alignment and temporal text alignment.
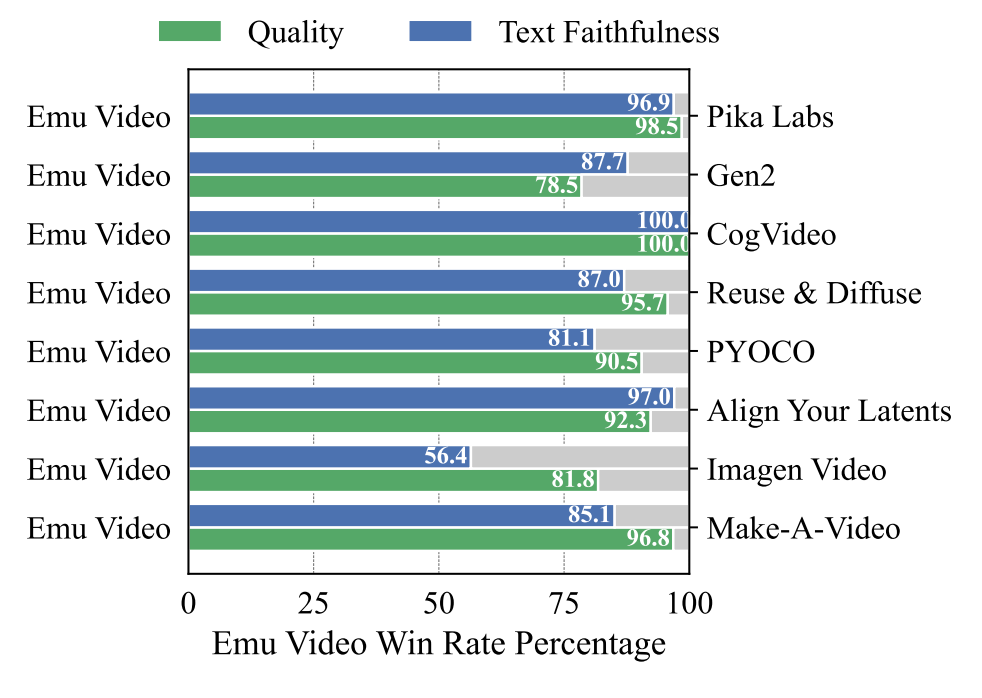
By this measure, Emu Video clearly outperforms all previous prompt-to-video models: in human evaluations, videos generated using the Meta model were preferred in quality and quantity over those generated using Pika Labs in more than 95 percent of cases. Only Google's Imagen Video comes a little closer in terms of prompt accuracy but is still far behind (56.4%), also in terms of quality (81.8%).
Many more video examples and an interactive demo are available on the Emu Video website.
Emu Edit: Text-based image editing
Emu Edit aims to simplify various image manipulation tasks and enhance image editing capabilities.
The model provides free video editing through natural language prompts only, including local and global editing, background removal and addition, color and geometry transformations, detection and segmentation, and more.
The focus is on changing only those pixels that are relevant to the edit request. Pixels in the video that are not addressed by the prompt remain unaffected, according to Meta.
To train the model, Meta has developed a dataset of tens of millions of synthesized examples for 16 image processing tasks, each containing an input image, a description of the task to be performed, and the desired output image. The model also uses learned task embeddings to guide the generation process toward the correct processing type.
Emu Edit is also capable of generalizing new tasks such as image inpainting, super-resolution, and combinations of processing tasks with only a few labeled examples. This capability is particularly useful in scenarios where high-quality examples are rare.
The researchers also found that computer vision tasks significantly improved editing performance and that Emu Edit's performance also increases with the number of training tasks.
In evaluations, Emu Edit demonstrated superior performance over current methods, achieving new highs in qualitative and quantitative scores for a variety of image processing tasks.
The model significantly outperforms existing models in following editing instructions and preserving the visual quality of the original image, the researchers said. They plan to further improve Emu Edit and explore its potential applications.
Emu Video and Emu Edit can be used in a variety of ways, from creating animated stickers or GIFs to editing photos and images. However, Emu Video and Emu Edit are still purely research projects at this point. As with other AI models, Meta will likely look to integrate the capabilities of these generative models into its own communication products, such as Instagram and WhatsApp, to give users more ways to interact and express themselves.




