Meta and Ohio State unveil Early Experience as a new training method for language agents
A new training approach lets AI agents learn from their own actions instead of depending on external reward signals. The agents experiment with different actions and use the results to improve.
Traditional AI agents are usually trained on human demonstrations, but these cover only a limited set of scenarios and often fail to generalize to new problems. Researchers at Meta and Ohio State University have developed an alternative called "Early Experience," which allows agents to learn directly from their own interactions.
In this setup, the agent doesn't just copy expert moves. It also tries out alternative actions and observes what happens, turning these experiences into extra training data without external rewards.
The study positions Early Experience as a middle ground between imitation learning, which relies on static expert data, and reinforcement learning, which needs clear reward signals that are often missing in real-world environments.
Two approaches for self-directed learning
The researchers developed two main techniques. The first, implicit world modeling, teaches the agent to predict what will happen after it takes certain actions. For example, if it clicks on a website, it learns to anticipate the next page. These predictions then become targets for training.
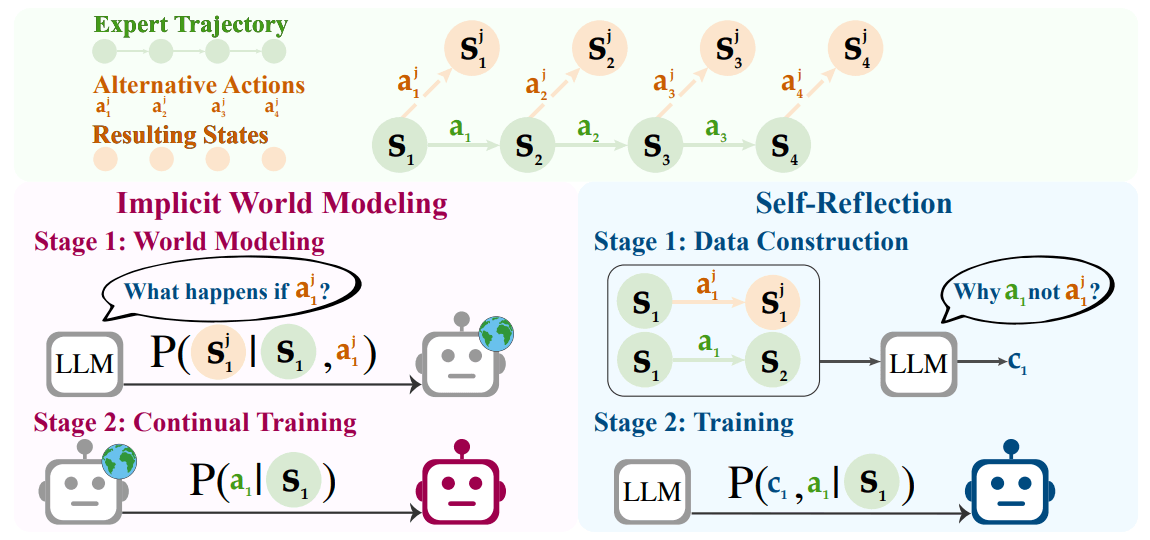
The second method, called self-reflection, has the agent compare its own actions to expert moves and generate natural language explanations for why the expert's action was superior. In an online shopping scenario, for example, the agent might explain that a more expensive item went over budget.
Both methods use the agent's own actions and their outcomes as learning signals, removing the need for outside evaluations.
Testing shows clear gains
The team tested Early Experience in eight different environments, including website navigation, simulated household chores, scientific experiments, multi-step tool use, and complex planning tasks like travel arrangements.
They ran experiments with three relatively small language models: Llama-3.1-8B, Llama-3.2-3B, and Qwen2.5-7B. Across all tasks, both Early Experience methods beat standard training approaches. On average, success rates rose by 9.6 percentage points, and performance in new scenarios improved by 9.4 percentage points.
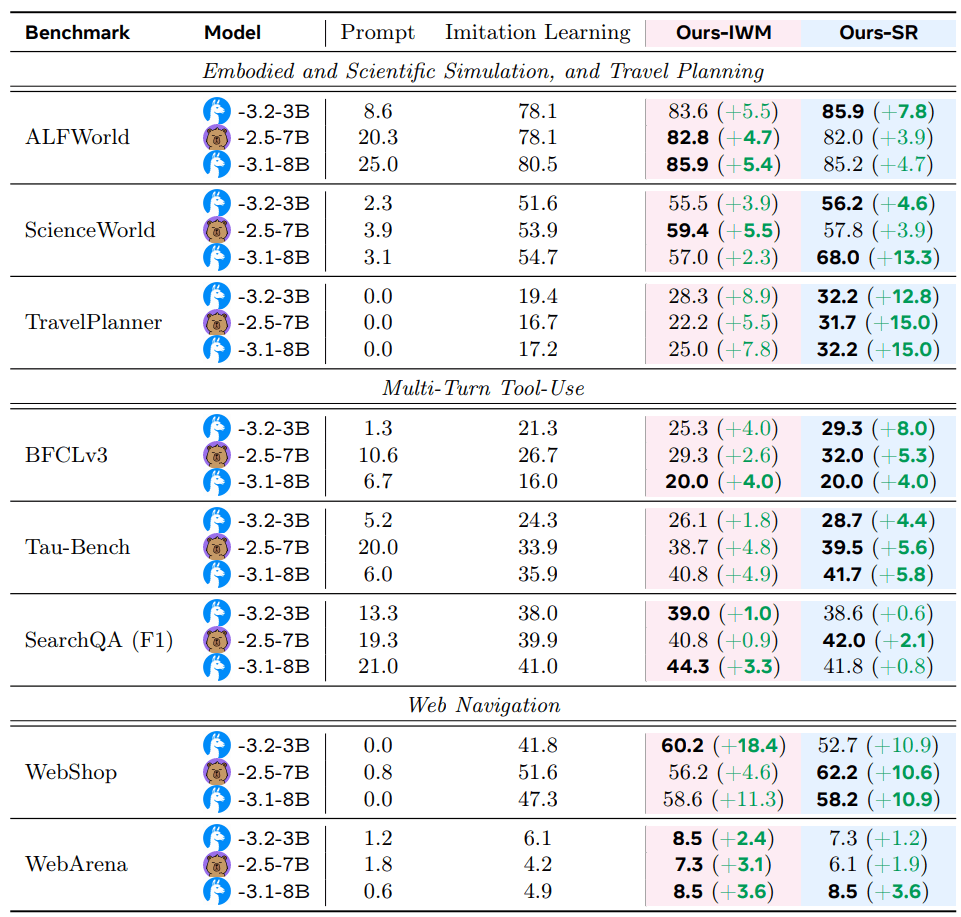
The biggest gains appeared on harder problems. In travel planning, self-reflection boosted results by up to 15 percentage points, while in online shopping, implicit world modeling improved scores by as much as 18.4 percentage points.
Laying the groundwork for reinforcement learning
Some environments offer reward signals for traditional reinforcement learning, so the researchers wanted to know if Early Experience could help models get even more out of this approach. They ran tests in three different domains: first, they trained models using various methods, then put all of them through the same reinforcement learning process.
The outcome was straightforward: models that started with Early Experience training consistently outperformed the others after RL. In fact, the performance gap sometimes got even wider as reinforcement learning progressed.
The study concludes that Early Experience can build strong systems even without rewards, and it makes later reinforcement learning even more effective. For now, it looks like a practical bridge between today's training approaches and what's coming next.
Scaling to larger models
Tests with models up to 70 billion parameters showed that Early Experience also works with much larger systems. Even when using resource-efficient LoRA updates, the improvements held up.
The team also looked at how many expert demonstrations are needed. Early Experience stayed ahead even with less data. In some tests, using just one eighth the original number of demonstrations was enough to outperform standard training with the full dataset. This lines up with earlier studies showing that a small number of examples can be enough to reach competitive results.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.