Meta's Fairy is a fast video-to-video synthesis model that shows how AI can bring more creative freedom to video editing.
Meta's GenAI team has introduced Fairy, a new model for video-to-video synthesis that is faster and more temporally consistent than existing models.
The research team demonstrates Fairy in several applications, including character/object replacement, stylization, and long-form video generation. Simple text prompts, such as "in the style of van Gogh," are sufficient to edit the source video. For example, the text command "Turn into a Yeti" turns an astronaut in a video into a Yeti (see video below).
Video: Meta, Wu et al.
Visual coherence is particularly challenging because there are countless ways to alter a given image based on the same prompt. Fairy uses cross-frame attention, "a mechanism that implicitly propagates diffusion features across frames, ensuring superior temporal coherence and high-fidelity synthesis"
The model can generate 512x384 pixel videos with 120 frames (4 seconds at 30 fps) in just 14 seconds, making it at least 44 times faster than previous models. Like Meta's Emu video models, Fairy is based on a diffusion model for image processing that has been enhanced for video editing.
Fairy processes all frames of the source video without temporal downsampling or frame interpolation, and resizes the horizontal aspect of the output video to 512 while preserving the aspect ratio. In tests with six A100 GPUs, Fairy was able to render a 27-second video in 71.89 seconds with high visual consistency.
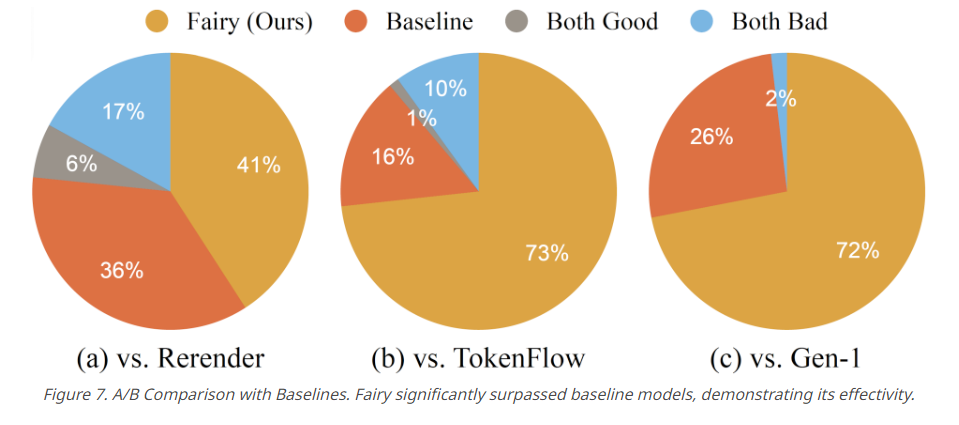
Fairy's performance was tested in an extensive user study of 1000 generated samples. Both human judgment and quantitative metrics confirmed that Fairy outperformed the three models Rerender, TokenFlow, and Gen-1.
Fairy still has problems with dynamic effects
The model currently has problems with environmental effects such as rain, fire or lightning that either do not fit well into the overall scene or simply produce visual errors.


According to the researchers, this is due to the focus on temporal consistency, which results in dynamic visual effects such as lightning or flames appearing static or stagnant rather than dynamic and fluid.
Nevertheless, the research team believes their work represents a significant advance in the field of AI video editing, with a transformative approach to temporal consistency and high-quality video synthesis.