Microsoft introduces Phi-4-mini-flash-reasoning with up to 10x higher token throughput

Microsoft has introduced Phi-4-mini-flash-reasoning, a lightweight AI model built for scenarios with tight computing, memory, or latency limits. Designed for edge devices and mobile apps, the model aims to deliver strong reasoning abilities without demanding hardware.
Phi-4-mini-flash-reasoning packs 3.8 billion parameters and builds on the Phi-4 family introduced in December, with a focus on mathematical reasoning.
At the core of the new model is an updated architecture called SambaY, now featuring a Gated Memory Unit (GMU) and "differential attention." Traditional transformers rely on complex attention in every layer to decide which parts of the input matter most.
The GMU streamlines this by replacing heavy cross-attention operations with a simple element-wise multiplication between the current input and a memory state from an earlier layer. This allows the model to dynamically recalibrate which tokens to focus on without the usual computational overhead.
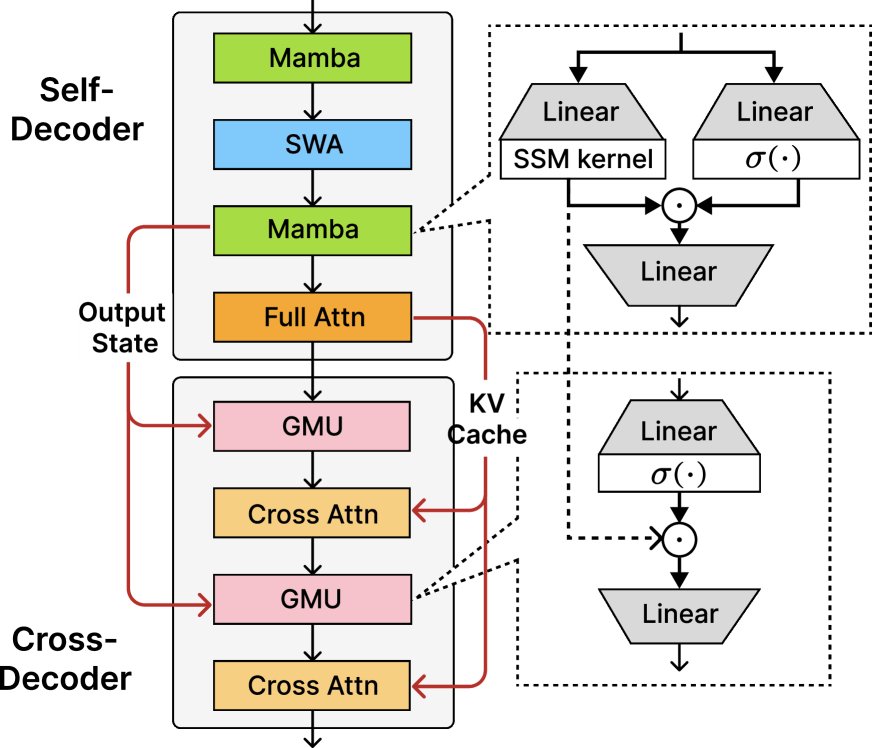
SambaY mixes several attention mechanisms: a single full-attention layer creates a key-value cache that later layers can access, while GMUs take the place of about half the cross-attention layers, letting layers share information through lightweight multiplications. This approach slashes both memory use and compute requirements. In typical models, data transfers between memory and processor climb as sequence length grows, but with SambaY, this remains mostly flat.
A new architecture for more efficient reasoning
These architectural changes bring a significant boost in performance. Microsoft says Phi-4-mini-flash-reasoning delivers up to ten times higher throughput and cuts average latency by a factor of two to three compared to its predecessor. However, these results are based on tests with industrial GPUs, not the low-resource devices the model is meant for.
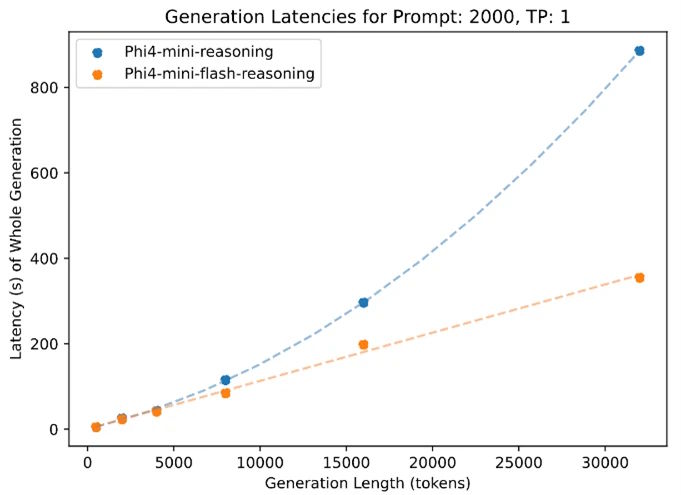
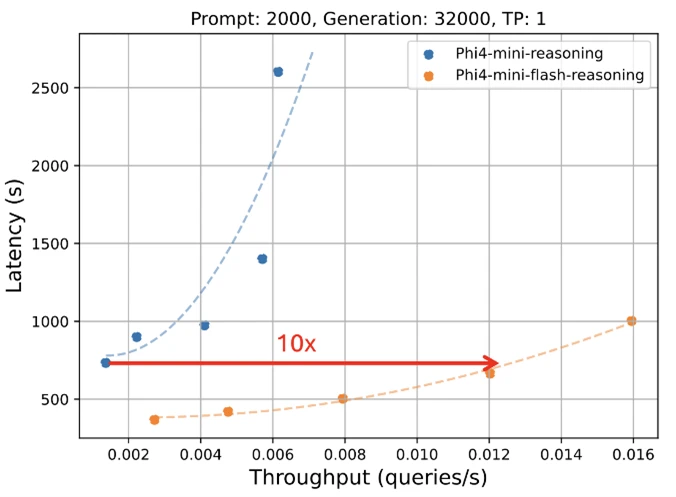
Phi-4-mini-flash-reasoning also excels at handling long contexts. The model supports a context window of up to 64,000 tokens and can maintain its speed and performance even at maximum capacity. Microsoft cites the efficiency of the SambaY design, which keeps processing speeds steady even as sequence length increases—a clear advantage over standard transformer models that tend to slow down in these scenarios.
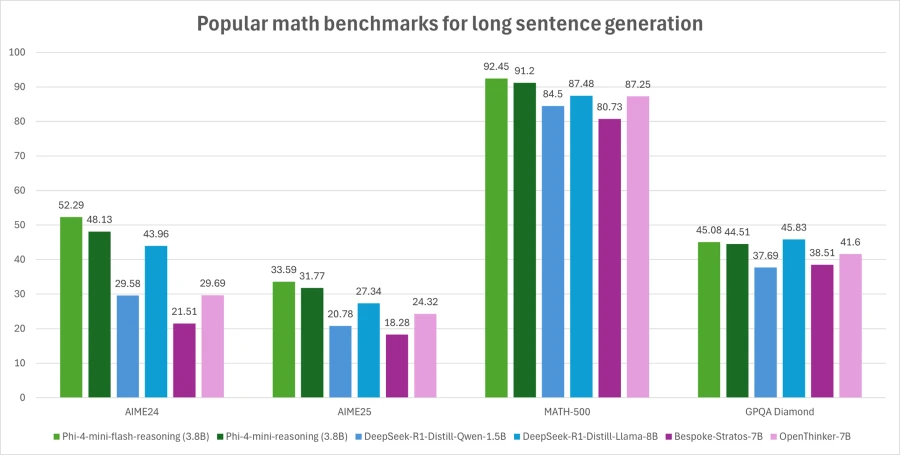
Outperforming larger models in reasoning benchmarks
The flash version stands out in benchmarks. Phi-4-mini-flash-reasoning was trained on five trillion tokens from the same data as Phi-4-mini, including synthetic data, using 1,000 A100 GPUs over 14 days.
In testing, it consistently beat the base model, especially on knowledge-intensive and programming tasks, with performance gains of several percentage points. The model also did better in math and scientific reasoning, all without the resource-heavy reinforcement learning step used in previous versions.
Phi-4-mini-flash-reasoning is available on Hugging Face, and Microsoft has released code examples in the Phi Cookbook. The full training codebase is open-sourced on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.