Microsoft releases new Phi 3.5 open-source language and vision models

Microsoft has released three new open-source AI models in its Phi series: mini-instruct, MoE-instruct, and vision-instruct. These models excel at LLM reasoning and support multiple languages, but have limitations in factual knowledge and safety.
Designed for commercial and scientific use, the Phi series generally aims to create highly efficient AI models using high-quality training data, although Microsoft hasn't yet shared details about the training process for Phi-3.5.
For the vision model, the company says it used "newly created synthetic, 'textbook-like' data for the purpose of teaching math, coding, common-sense reasoning, general knowledge of the world," in addition to other high-quality and filtered data.
Microsoft says these new models are ideal for applications with limited resources, time-sensitive scenarios, and tasks requiring strong logical reasoning within an LLM's capabilities.
The Phi-3.5-mini-instruct model, with 3.8 billion parameters, is optimized for low-resource environments. Despite its small size, it performs well in benchmarks, especially for multilingual tasks.
The Phi 3.5 MoE-instruct model has 16 experts, each with 3.8 billion parameters, for a total of 60.8 billion. However, only 6.6 billion parameters are active when using two experts, which is enough to match larger models in language comprehension and math, and to outperform some in reasoning tasks.
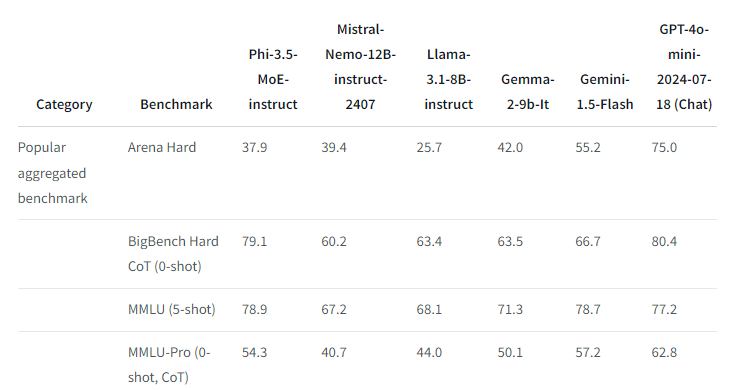
It's often close to GPT-4o-mini performance, but keep in mind that these are just benchmarks, and word on the street is that Phi models have shown subpar real-world performance.
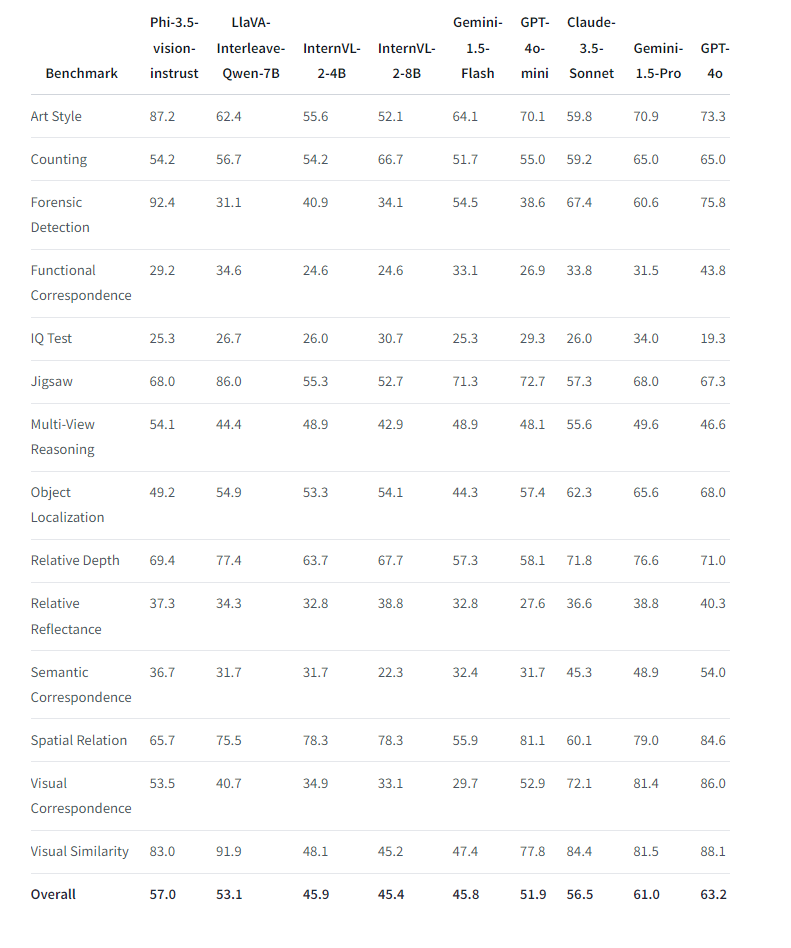
The Phi-3.5-vision-instruct model, a multimodal system with 4.2 billion parameters, can process text and images. It's suitable for tasks such as image understanding, OCR, and diagram understanding. It outperforms similarly sized models in benchmarks, and competes with larger models in multi-image processing and video summarization.
Phi's context window gets an upgrade
All Phi 3.5 models support a context length of up to 128,000 tokens, making it useful for long document summaries and multilingual context retrieval. It outperforms Google's Gemma 2 models, which are limited to 8,000 tokens.
However, like all LLMs, it is likely to suffer from the "lost in the middle" problem when processing large documents. This also applies to image processing.
The small size of the models limits their factual knowledge, according to Microsoft, potentially leading to higher than average inaccuracies. Microsoft suggests pairing Phi-3.5 with a search method such as RAG to address this weakness.
Like other language models, Phi models can produce biased or offensive output. They reject unwanted content in English, even when prompted in other languages, but are more vulnerable to complex prompt injection techniques in multiple languages.
The Phi 3.5 models are available under the MIT license on Hugging Face and through Microsoft's Azure AI Studio. They require specialized GPU hardware like NVIDIA A100, A6000, or H100 to support flash attention.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.