
Until now, diffusion models could only generate high-quality images with many iterations. A team at MIT has now succeeded in compressing the process into a single step - with a quality comparable to multistep Stable Diffusion.
Scientists at MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) have developed a new method that can dramatically speed up image generation using diffusion models such as Stable Diffusion or DALL-E.
Instead of the previously required 20 or more iteration steps, the new method called Distribution Matching Distillation (DMD) only needs a single step.
Similar experiments have already been conducted, including directly by Stability AI, the company behind Stable Diffusion. However, the quality of the images generated with the MIT method is said to be comparable to the more computationally intensive methods.
"This advancement not only significantly reduces computational time but also retains, if not surpasses, the quality of the generated visual content," says Tianwei Yin, a PhD student in electrical engineering and computer science at MIT and lead author of the study.
Diffusion models generate images by gradually adding structure to a noisy initial state until a clear image emerges. This process typically requires hundreds of iterations to perfect the image.
MIT's new approach is based on a "teacher-student" model: A new AI model learns to mimic the behavior of more complex original models for image generation. DMD combines the scoring principles (real, fake) of Generative Adversarial Networks (GANs) with those of diffusion models.
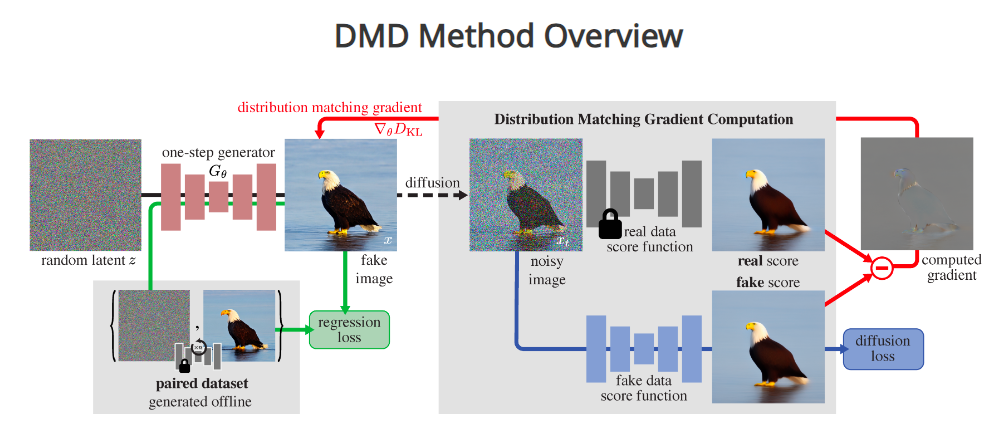
For the new student model, the researchers used pre-trained networks, which simplified the process. By copying and refining the parameters of the original models, they achieved fast training convergence of the new model. The architectural basis is preserved.
"This enables combining with other system optimizations based on the original architecture to further accelerate the creation process," says Yin.

In tests, DMD has performed consistently well. When generating images from certain classes of the ImageNet dataset, DMD is the first one-step diffusion technique to produce images that are nearly equivalent to the images of the more complex original models.


The Fréchet Inception Distance (FID) was only 0.3. It measures the quality and diversity of the generated images based on the statistical distribution of features such as colors, textures, and shapes of the generated images compared to real images. A low FID value indicates higher quality and similarity of the generated images to the real images.
DMD also achieves the state of the art in industrial-scale text-to-image generation with one-step generation. For more demanding text-to-image applications, there is still a small quality gap and room for improvement, the researchers say.
The performance of images generated with DMD also depends on the capabilities of the teacher model used during the distillation process. In its current form, with Stable Diffusion v1.5 as the teacher model, the student inherits limitations such as the inability to generate detailed text or to generate only "small faces".



