OpenAI quietly funded independent math benchmark before setting record with o3

OpenAI's involvement in funding FrontierMath, a leading AI math benchmark, only came to light when the company announced its record-breaking performance on the test. Now, the benchmark's developer Epoch AI acknowledges they should have been more transparent about the relationship.
FrontierMath, introduced in November 2024, tests how well AI systems can tackle complex mathematical problems that require advanced reasoning and problem-solving skills - the kind of tasks that typically stump even the most sophisticated AI systems. The benchmark's problems were created by a team of over 60 leading mathematicians.
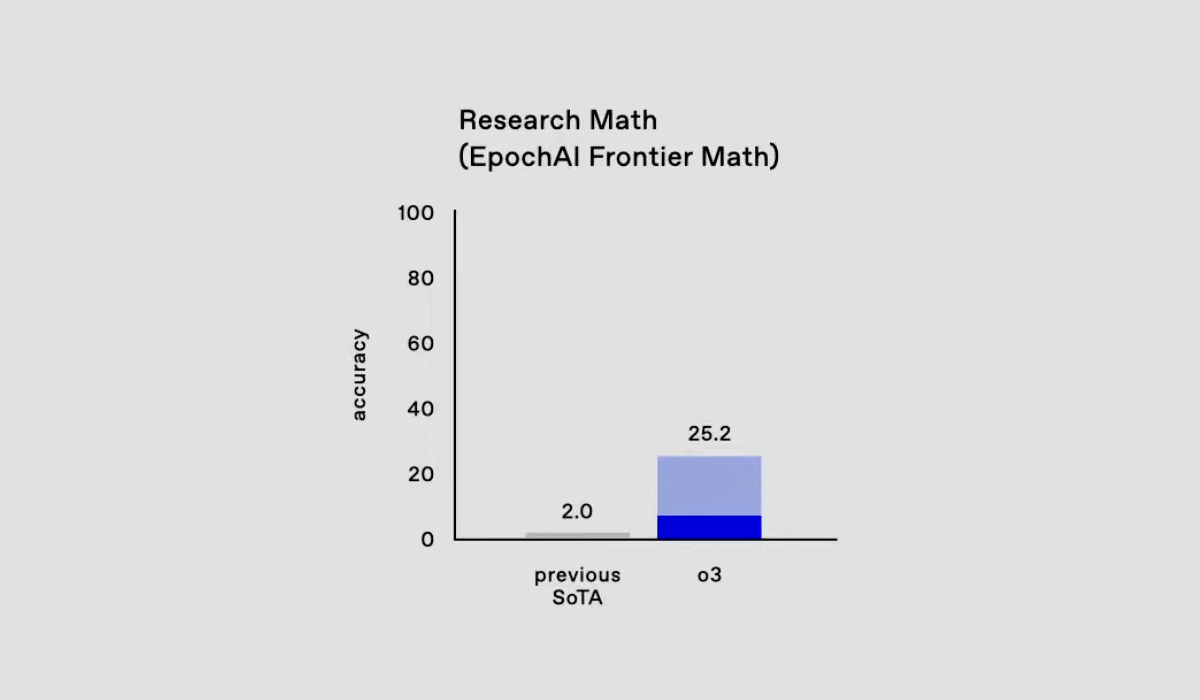
The connection between OpenAI and FrontierMath emerged on December 20, the same day OpenAI unveiled its new o3 model. The system achieved an unprecedented 25.2 percent success rate on the benchmark's challenging math and logic problems - a massive jump from previous models that couldn't solve more than two percent of the questions.
Epoch AI, which developed the benchmark, had signed an agreement preventing them from revealing OpenAI's financial support until o3's announcement. They acknowledged the connection in a footnote after updating their research paper for the fifth time, simply stating: "We gratefully acknowledge OpenAI for their support in creating the benchmark."
According to a post on LessWrong, the more than 60 mathematicians who helped create the benchmark problems remained in the dark about OpenAI's involvement - even after o3's announcement. While these experts had signed non-disclosure agreements, the agreements only covered keeping the problems themselves confidential. Most believed their work would stay private and be used exclusively by Epoch AI, according to the post.
OpenAI has access to "much but not all" FrontierMath benchmark data
Tamay Besiroglu from Epoch AI admits they made mistakes. "We should have pushed harder for the ability to be transparent about this partnership from the start, particularly with the mathematicians creating the problems," he writes.
According to Besiroglu, OpenAI got access to many of the math problems and solutions before announcing o3. However, Epoch AI kept a separate set of problems private to ensure independent testing remained possible.
They also made a verbal agreement with OpenAI that prohibits the company from using the materials to train their models - a safeguard against gaming the benchmark and preventing the problems from becoming public.
"For future collaborations, we will strive to improve transparency wherever possible, ensuring contributors have clearer information about funding sources, data access, and usage purposes at the outset," Besiroglu writes.
While this lack of transparency doesn't undermine the benchmark's quality or significance per se, such an important tool for AI evaluation deserved complete openness from the start, especially since mathematical reasoning is a major weakness of language models and improved logical performance could signal a breakthrough.
"I believe OAI has been accurate with their reporting on it, but Epoch can't vouch for it until we independently evaluate the model using the holdout set we are developing," writes Epoch AI lead mathematician Elliot Glazer.
The situation highlights how complex AI benchmarking has become - creating these benchmarks is expensive and intricate work. While test results can be difficult to translate into real-world performance and depend heavily on testing methods and model optimization, these same results play a crucial role in attracting attention and investment.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.