OpenAI promises a “much better version” of its Olympic math gold model in the coming months

OpenAI researcher Jerry Tworek is sharing early details about a new AI model that could mark a notable leap in performance in certain areas.
The so-called "IMO gold medal winner" model is set to debut in a “much better version” in the coming months. As Tworek notes, the system is still under active development and is being prepared for broader public release.
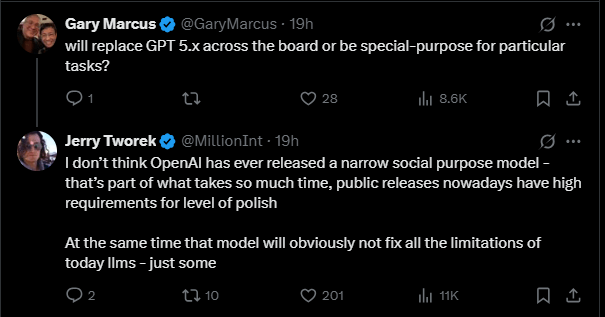
When OpenAI critic Gary Marcus asked whether the model is intended to replace GPT-5.x or serve as a task-specific specialist, Tworek said OpenAI has never released a narrowly focused model. He explained that “public releases nowadays have high requirements for level of polish,” and added: “At the same time that model will obviously not fix all the limitations of today llms - just some.”
The model’s ability to generalize beyond math has sparked debate. During its presentation, OpenAI emphasized that it had only been “very little” optimized for the International Mathematical Olympiad. Rather than being a math-specific system, it’s built on more general advances in reinforcement learning and compute—without relying on external tools like code interpreters. Everything runs through natural language alone.
That distinction matters because reinforcement learning still struggles with tasks that lack clear-cut answers, and many researchers consider this an unsolved problem. A breakthrough here would help validate the idea that scaling reasoning models justifies the massive increases in compute, one of the central questions in the ongoing debate over a possible AI bubble.
Verifiability, not specificity, is the real bottleneck
Former OpenAI and Tesla researcher Andrej Karpathy has pointed to a deeper structural constraint: in what he calls the “Software 2.0” paradigm, the key challenge isn’t how well a task is defined, but how well it can be verified. Only tasks with built-in feedback—like right-or-wrong answers or clear reward signals—can be efficiently trained using reinforcement learning.
“The more a task/job is verifiable, the more amenable it is to automation in the new programming paradigm,” Karpathy writes. “If it is not verifiable, it has to fall out from neural net magic of generalization fingers crossed, or via weaker means like imitation.” That dynamic, he says, defines the “jagged frontier” of LLM progress.
Software 1.0 easily automates what you can specify. Software 2.0 easily automates what you can verify.
That’s why domains like math, coding, and structured games are advancing so quickly, sometimes even surpassing expert human performance. The IMO task fits squarely into this category. In contrast, progress in less verifiable areas—like creative work, strategy, or context-heavy reasoning—has stalled.
Tworek and Karpathy’s views align: the IMO model shows that verifiable tasks can be systematically scaled using reasoning-based methods, and there are many such tasks. But for everything else, researchers are still relying on the hope that large neural networks will generalize well beyond their training data.
Why everyday users may not notice the difference
Even if models outperform humans in tightly verifiable domains like math, that doesn’t mean everyday users will feel the impact. These gains could still accelerate research in areas like proofs, optimization, or model design, but they’re unlikely to change how most people interact with AI.
OpenAI has recently noted that many users no longer recognize genuine improvements in model quality because typical language tasks have become trivial, at least within the known limits of LLMs, such as hallucinations or factual mistakes.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.