


OpenAI's new AI model looks like a giant leap in text and video-to-video generation. But the model's potential is much greater, OpenAI says. It could become a world simulator.
Yesterday, OpenAI unveiled Sora, a large AI model for video and image generation. With Sora, OpenAI can generate videos up to a minute long, in different aspect ratios and resolutions, and with unprecedented quality.
Sora is based on a transformer architecture similar to that used in language models, and combines it with diffusion techniques from image generators. The model ingests videos and images during training and breaks them down into simpler forms and smaller pieces. Sora can then generate new visual content from these pieces.
Unlike many previous works that focus on specific categories of visual data, shorter videos, or videos of a fixed size, Sora is a visual data generalist. It can generate videos and images of different lengths, aspect ratios, and resolutions. But that's not all.
Sora can generate interactive 3D worlds
OpenAI does not comment on the training data it uses. However, the scenes shown by OpenAI so far contain visual clues that OpenAI uses very high quality synthetic training data, photorealistic scenes generated by a game engine, instead of or in addition to real footage.
This would also allow the company to avoid or mitigate potential copyright issues known from text and image generators. Nvidia's Jim Fan and others speculate that the AI was trained with synthetic data generated by Unreal Engine 5.
For example, in the video below, the dust behind the car looks like it is in a video game, especially since it only appears behind the car and not around it as it would in reality.

Video: OpenAI
In this short sequence, the animations of the two main protagonists are deceptive: although they look realistic, their uniformity is reminiscent of a video game. Human movements are more varied.
Video: OpenAI
Another indication of synthetic data training is that Sora can generate videos with dynamic camera movements and three-dimensional coherence. As the camera moves and rotates, people and scene elements move together in three-dimensional space.
Sora can also simulate actions that affect the state of the generated scene. For example, a painter can leave new lines on a canvas that change over time, or a man can eat a burger and leave bite marks. Elements in videos, such as waves and ships, can interact with each other in a physically correct way.
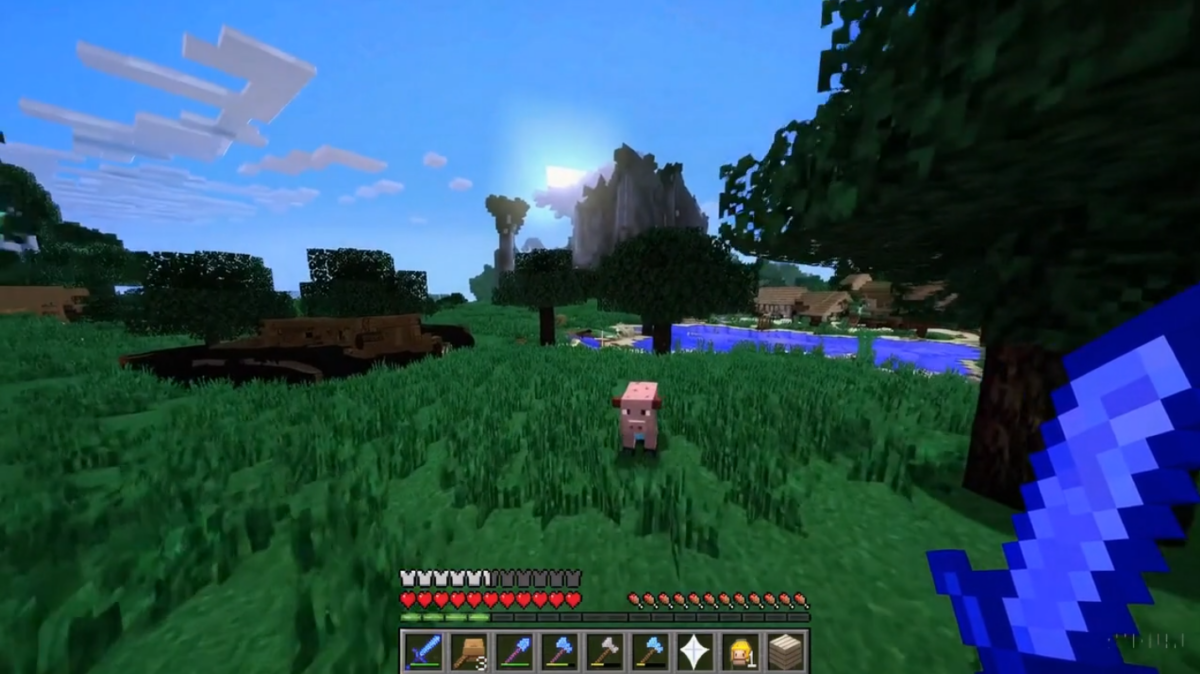
The model is not only capable of generating frames, but also interactions within a world, similar to a video game. OpenAI demonstrates this using Minecraft as an example: Sora can generate a Minecraft world and interact with it, much like the original game. All you need is the word "Minecraft" in your prompt.
Video: OpenAI
This goes far beyond video generation and indicates a fundamental change in the way game graphics are created. If you need even more detailed proof of this, you can watch a scene in a demo that looks like it's from a racing game. It shows how Sora can display the same sequence in different variations, from a jungle to an underwater world to cyberpunk to retro pixel graphics, using only text commands.
Image: OpenAIOf course, there are still many unanswered questions, such as computing effort and depth of interaction. But after Nvidia's DLSS, the next, even more far-reaching upheaval in computer graphics is on the horizon.
And despite its impressive capabilities, Sora currently has some limitations as a simulator, according to OpenAI. For example, Sora does not correctly model the physics of many basic interactions, such as breaking glass.
Other interactions, such as eating food, do not always result in correct state changes of objects, and a common error is inconsistencies that develop over time or the spontaneous appearance of objects.
However, these problems could be solved by further scaling the models, according to OpenAI: "Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world."
The idea that video models can serve as world models because they can represent the complex variety of everyday life better than, say, pure text and image models is not fundamentally new.
Video AI startup RunwayML recently unveiled its world model research, and startup Wayve is using video models to simulate traffic for self-driving cars.
Meta has been collecting thousands of hours of first-person video for years to train AI assistance systems for everyday situations, and on the day of Sora's unveiling, it showed V-JEPA, a new architecture for predicting and understanding complex interactions in video.
However, OpenAI's Sora eclipses all previous approaches and models that we know of.