
In June 2023, Wayve, a British startup specializing in AI for autonomous driving, unveiled GAIA-1 (Generative Artificial Intelligence for Autonomy), a generative model for autonomous car training data. Now the company is reporting progress on its development.
Imagine, for example, a pedestrian jumping out from behind a truck in the fog, while at the same time a motorcyclist is about to pass you and a cyclist is approaching from ahead. It's a realistic scenario, but how many miles would you have to drive and film to capture this exact scene?
GAIA-1 uses text, image, video, and action data to create synthetic videos of a variety of traffic situations that can be used to train autonomous cars. The goal is to fill the data gap created by the complexity of road traffic: it is almost impossible to capture every conceivable traffic situation on video.
From video to the world model
According to Wayve, GAIA-1 is not a standard generative video model, but a generative "world model" that learns to understand and decipher the most important concepts of driving. It understands and separates concepts such as different vehicles and their characteristics, roads, buildings, or traffic lights.
GAIA-1 learns to represent the environment and its future dynamics, providing a structured understanding of the environment that can be used to make informed decisions while driving.
Predicting future events is a critical aspect of autonomous systems, as accurate prediction of the future allows autonomous vehicles to anticipate and plan their actions, increasing safety and efficiency on the road.
Since its initial unveiling in June, the team has optimized GAIA-1 to efficiently generate high-resolution video and improved the quality of the world model through extensive training. The model, which now has nine billion parameters (up from one billion in the June version), also allows precise control of vehicle behavior and scene characteristics in videos. It is intended to be a powerful tool for training and validating autonomous driving systems.
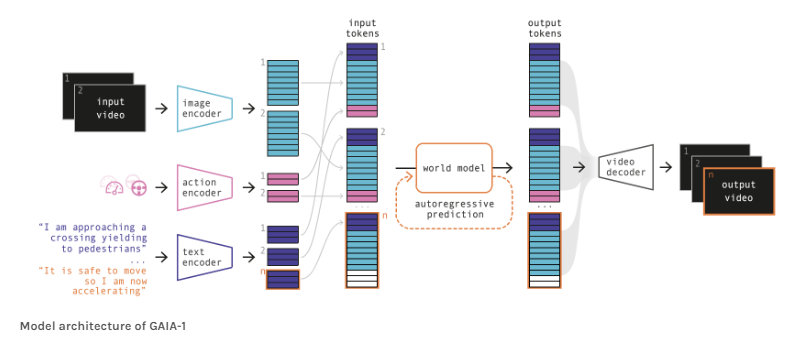
Wayve's GAIA-1 model was trained with 4,700 hours of proprietary driving data collected in London, UK, between 2019 and 2023. The model architecture includes dedicated encoders for each input modality (video, text, and action), the world model, an autoregressive transformer, and a video decoder, a video diffusion model that translates predicted image elements back into pixel space.

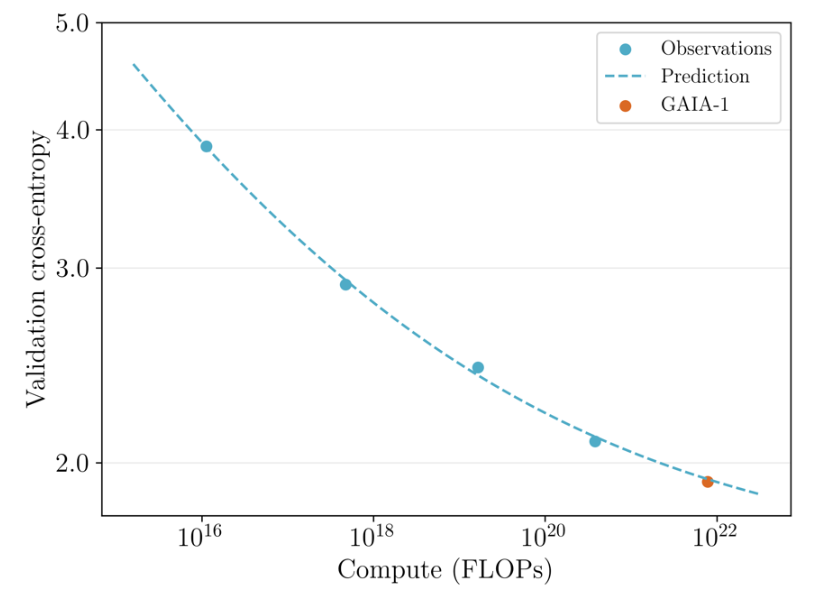
Scaling laws also apply to video generation
The world modeling task in GAIA-1 is very similar to the approach commonly used for large language models (LLMs), where the task is simplified to predicting the next token. In GAIA-1, this methodology is applied to video modeling instead of language.
This suggests that GAIA-1's performance and efficiency in video generation will continue to improve as model size and training datasets increase, similar to the scaling patterns observed for large language models in their respective domains. The developers continue to see "significant room for improvement" with more data and processing power in training.
GAIA-1 models different futures and responds to sudden changes
GAIA-1 can predict different futures from contextual video images of the past. This includes the behavior of pedestrians, cyclists, motorcyclists, and oncoming traffic, allowing the model to consider interactions with other road users and react to situations.
In one example, the camera vehicle is forced to leave its lane by steering to the right and then steering back. The oncoming vehicle responds with evasive maneuvers to avoid a collision. This demonstrates the model's ability to anticipate and react to potential road hazards, Wayve writes.
GAIA-1 can also be controlled by pure text input. For example, the model can generate different weather conditions for driving scenes with the text command "It is" followed by "sunny", "rainy", "foggy" or "snowy". It can also create scenes with different lighting conditions using text commands such as "It is daytime, we are in direct sunlight," "The sky is gray," "It is dusk," and "It is night."
On its website, Wayve demonstrates the model's behavior with numerous examples.
Wayve also discusses the limitations of GAIA-1: The autoregressive generation process, while effective, requires a lot of computation, making the generation of long videos very computationally intensive.
In addition, the current model is mainly focused on predicting single camera outputs, whereas for autonomous driving an overall view from all surrounding viewpoints is critical.
Future work will extend the model's capabilities to capture this broader perspective and optimize its generation efficiency to make the technology more applicable and efficient, Wayve writes.
In addition to GAIA-1, Wayve is also developing Lingo-1, an autonomous driving system that combines machine vision with text-based logic to explain decisions and situations on the road. Among other things, this text-based logic could increase the sense of safety in cars by making the AI's decisions feel less like a "black box."




