Wayve, a British startup specializing in AI-based autonomous driving, unveils its new model: Lingo-1, which combines machine vision with text-based logic.
Humans have to make decisions on the road all the time: When do we step on the gas, when do we take our foot off the gas, when do we pass or when do we hold back?
Self-driving cars have to make the same decisions. But unlike humans, they can't justify their decisions - not yet. Lingo-1 aims to change that.
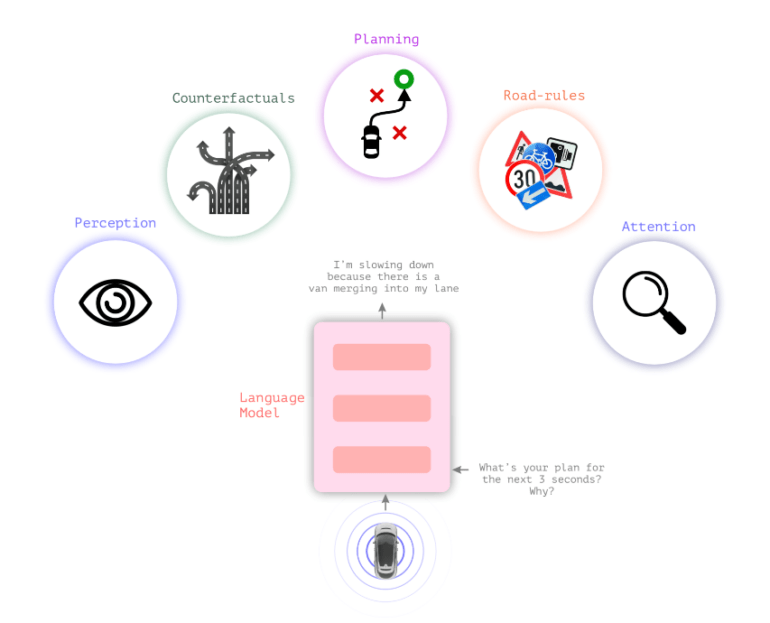
Lingo-1 combines language models with visual models
Typical autonomous driving systems rely on visual perception to make decisions. Wayve's new Lingo-1 visual language model inserts textual logic between visual perception and action, allowing the car to explain its actions.
For a driving decision and for the general traffic situation, the car continuously provides textual statements describing the current situation and justifying decisions, similar to a driver thinking aloud or a driving instructor wanting to support the learner's attention.
Video: Wayve
This textual logic could increase the sense of safety in cars by making their decisions seem less like a "black box". It could also contribute to the safety of autonomous vehicles by allowing the system to reason textually through traffic scenarios that are not included in the training data.
In addition, Lingo-1's behavior can be flexibly adjusted through simple text prompts, and it can be trained with additional examples written by humans without the need for extensive and costly visual data collection.
"Causal reasoning is vital in autonomous driving, enabling the system to understand the relationships between elements and actions within a scene," Wayve writes.

Video: Wayve
Instead of collecting thousands of visual examples of a car braking for a pedestrian, a few examples of the scene with brief text descriptions of how the car should behave in the situation and what factors to consider would suffice, Wayve writes.
Autonomous cars could benefit from general knowledge in large language models
The general knowledge of large language models could also improve driving models, especially in previously unknown situations.
"LLMs already possess vast knowledge of human behaviour from internet-scale datasets, making them capable of understanding concepts like identifying objects, traffic regulations, and driving manoeuvres. For example, language models know the difference between a tree, a shop, a house, a dog chasing a ball, and a bus that’s stopped in front of a school," Wayve writes.
Video: Wayve
Lingo-1 was trained using image, voice, and action data collected from Wayve drivers as they drove around London. According to Wayve, Lingo-1 currently achieves 60 percent of the accuracy of human drivers. The system has more than doubled its performance since initial testing in August and September through improvements to its architecture and training dataset.
Lingo-1 is limited in that it has only been trained on data from London and the UK. It can also generate incorrect answers, a common problem with LLMs, but Lingo-1 has the advantage of being based on real-world visual data, the company writes.
Technical challenges include the much-needed long context lengths for video descriptions in multimodal models, and integrating Lingo-1 into the closed-loop architecture directly in the autonomous vehicle.
In June, Wayve introduced GAIA-1, a generative AI model that can help alleviate the bottleneck caused by the limited supply of video data for training AI models on different traffic situations. GAIA-1 learns driving concepts by predicting the next frames in a video sequence, making it a valuable tool for training autonomous systems to navigate complex real-world scenarios.