OpenSeeker's open-source approach aims to break up the data monopoly for AI search agents
With just 11,700 training data points and a single training run, the AI search agent OpenSeeker achieves results that rival solutions from Alibaba and others. Data, code, and model are all openly accessible.
Powerful AI search agents—systems that autonomously search the internet for information across multiple steps—have so far been big tech's territory. OpenAI, Google, and Alibaba keep their training data locked down. Even projects that publish their model weights stay quiet about the data behind them.
This data monopoly has held back the open research community for close to a year, according to researchers at Shanghai Jiao Tong University. With OpenSeeker, the academic team aims to change that: all training data (MIT license), the code, and the model weights are openly available.
Web link structures replace language model guesswork for training data
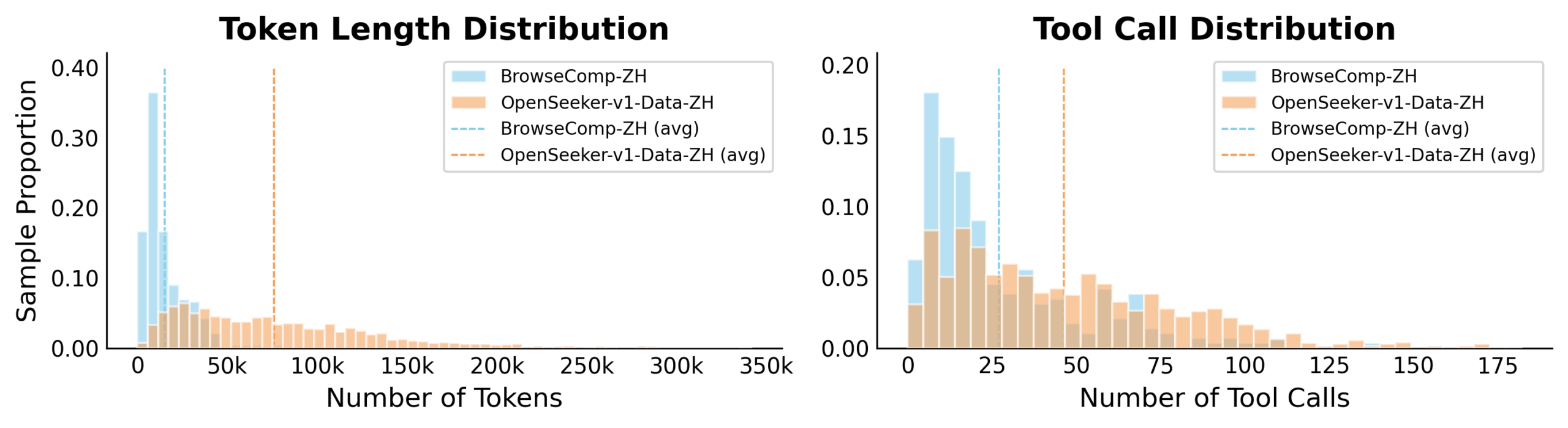
OpenSeeker builds on two core ideas for generating data. For question-answer pairs, the team uses the real link structure of the web as its foundation, generating questions from it. Starting from randomly selected seed pages within a web corpus (around 68 GB of English and 9 GB of Chinese data), the system follows hyperlinks to related pages and pulls out the most important information.
Specific names and terms then get swapped out for vague descriptions, so a search agent can't find the answer with a simple keyword search. This forces genuine multi-step search and reasoning.

A two-stage filter weeds out unusable questions: a strong base model must not be able to answer them without tools but must be able to solve them with full context. If either condition fails, the question gets tossed.
The second idea focuses on the search paths the model learns from. Web pages contain a lot of noise that drags down the quality of recorded solution paths. During data generation, a teacher model gets a cleaned-up summary of previous search results and makes better decisions based on that.
During training, the student model then sees the raw, uncleaned data but is still expected to reproduce the teacher's high-quality decisions. This forces it to figure out on its own how to separate signal from noise.
11,700 data points versus 147,000: data quality beats sheer volume
OpenSeeker is based on Qwen3-30B-A3B and was trained with just 11,700 data points in a single run using supervised fine-tuning, without any reinforcement learning or repeated tweaking.
According to the paper, the model hit 48.4 percent on the Chinese-language BrowseComp-ZH benchmark, beating Alibaba's Tongyi DeepResearch at 46.7 percent. Alibaba's model went through a three-stage process of extended pre-training, supervised fine-tuning, and reinforcement learning.
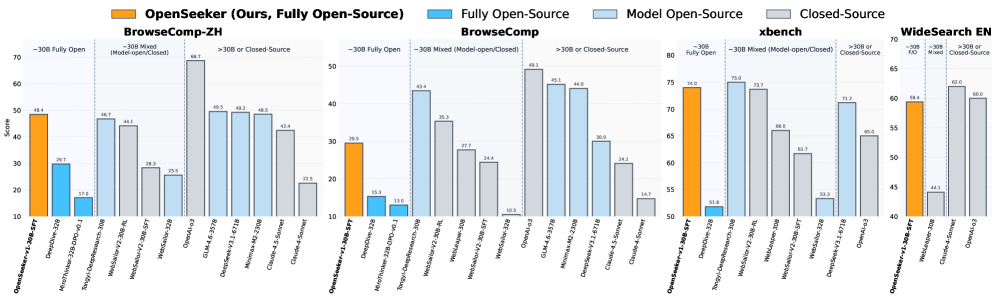
On OpenAI's English-language BrowseComp, OpenSeeker scores 29.5 percent - nearly double DeepDive's 15.3 percent, the previous leader among fully open agents.
A comparison with MiroThinker drives home how much data quality matters over raw quantity: that model was fed 147,000 training examples yet only manages 13.8 percent on BrowseComp-ZH. OpenSeeker hits 3.5 times that score with less than one-twelfth the data.
There's still a gap compared to the strongest proprietary systems, though. OpenAI's GPT-5-High hits 54.9 percent on BrowseComp, and DeepSeek-V3.2 with 671 billion parameters reaches 51.4 percent. OpenSeeker runs on a fraction of the model size and training effort.
The question of who gets access to high-quality training data has been a central issue in the AI industry for a while now. Last year, a research team released the Common Pile, an 8 TB text dataset built from openly licensed sources. So far, that hasn't done much to shake the dominance of commercial models.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.