Popular AI benchmark LMArena allegedly favors large providers, study claims

Researchers say the ranking system favors major providers like OpenAI, Google, and Meta. LMArena disputes the claims.
LMArena has become one of the most prominent public benchmarking platforms for large language models. The platform operates by presenting users with head-to-head comparisons of model responses, asking them to vote for the better answer. The resulting rankings are widely cited in the AI industry and frequently used by companies to showcase performance.
A new study, however, argues that these rankings are distorted by opaque processes and systemic advantages for large providers. The analysis is based on over 2 million model comparison records — or 2.8 million, according to co-author Sara Hooker on LinkedIn — collected between January 2024 and April 2025.
Private testing and selective publishing influence rankings
According to researchers from Cohere Labs, Princeton, and MIT, companies such as Meta, Google, and OpenAI are allowed to privately test numerous versions of their models before selecting one to appear in the public leaderboard.
Only the highest-performing variant is published, while others are removed. This process enables what the study refers to as "score gaming." In one example, Meta tested at least 27 versions before releasing Llama 4.
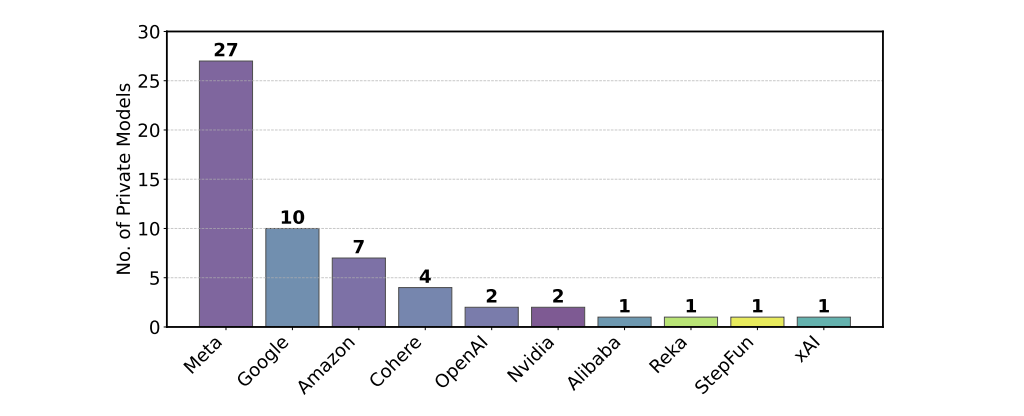
Meta later acknowledged deploying a Llama 4 chatbot optimized specifically for the benchmark after receiving criticism from users. When the company submitted the unoptimized "Maverick" model, it performed significantly worse in LMArena.
In controlled experiments, the researchers found that submitting multiple near-identical variants could substantially increase a model’s score. With just ten entries, a model could gain around 100 points — even when the differences between versions were minimal.
Unequal access to user data benefits larger vendors
Another reported issue involves how user data is distributed. Through API access, providers can collect data from model-vs-model interactions — including user prompts and preferences. But this data is not evenly shared. Models from companies like OpenAI and Google reportedly receive far more user interactions than those from smaller firms or open-source projects.
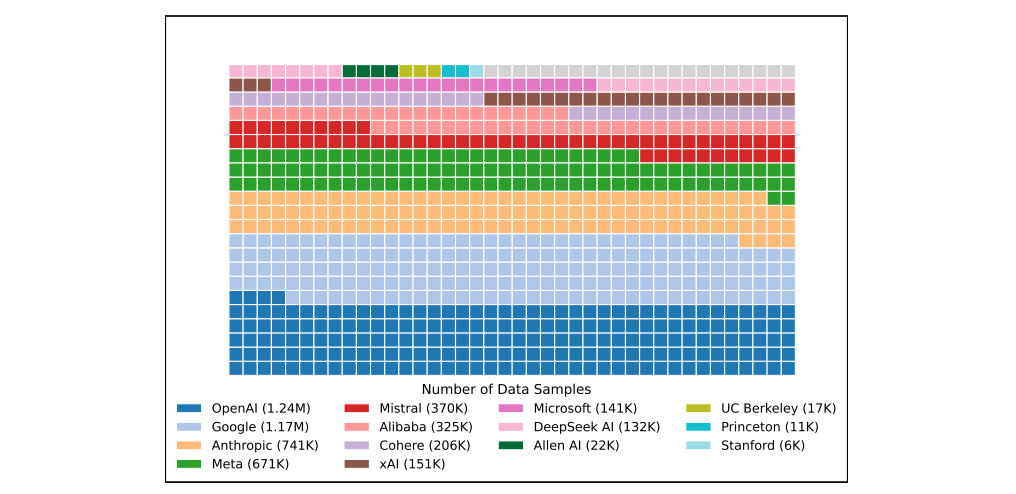
The study includes an experiment showing that training a model on more arena-derived data improves its ranking performance, even if the model performs slightly worse on external benchmarks. This suggests that models can be optimized specifically for the arena, without necessarily improving their overall quality.
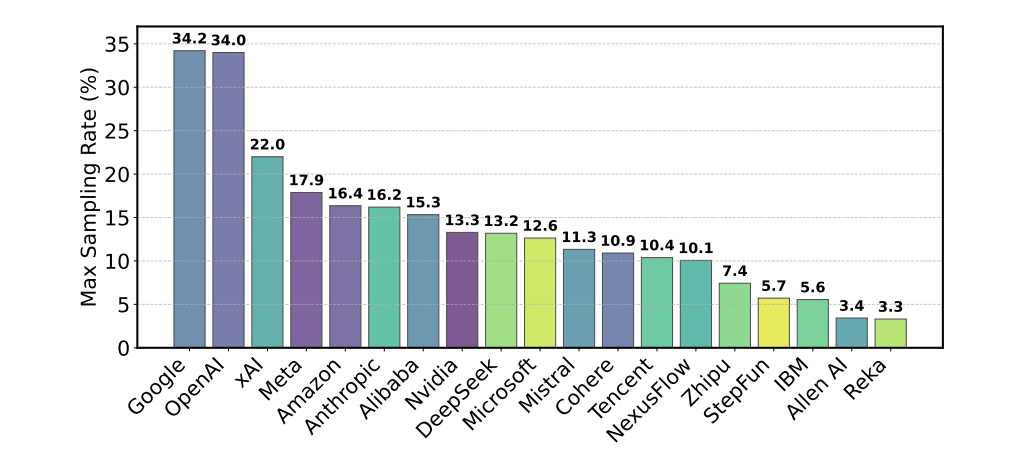
Researchers also point out that many models are removed from the platform without public notice, a pattern that disproportionately affects open-source models. Of the 243 models evaluated, 205 were deactivated without explanation, while only 47 were officially marked as deprecated. According to the study, removing models without transparency can distort the rankings, particularly when those models previously served as key reference points for comparison.
LMArena operators reject the findings
The team behind LMArena rejects the study's conclusions. In a statement posted to X, they write that the platform's rankings "reflect millions of fresh, real human preferences" and describe pre-submission testing as a legitimate method for identifying which model variant best aligns with user expectations.
"If pre-release testing and data helps models optimize for millions of people's preferences, that's a positive thing," they write.
They also state that the number of variants tested is up to individual providers. While all developers are welcome to submit models, the team acknowledges that support may vary. "Within our capacity, we are trying to satisfy all requests for testing we get from model providers," the company writes.
The team emphasizes that only the final, publicly released model is included in the rankings — not results from internal tests. They also note that LMArena's source code and millions of user interactions are publicly accessible, and that the platform is designed to be open.
Some of the study's recommendations — such as implementing fairer procedures for selecting which models are shown to users — are under review. However, the team states that "there are also a number of factual errors and misleading statements."
They particularly dispute the claim that submitting multiple model variants automatically provides an advantage. According to the team, the study's simulations assume all test variants are of equal strength and that the top performers are selected randomly. They argue that this assumption is unrealistic, as different model versions often vary in capabilities.
Researchers call for greater transparency and fairness
The study's authors are calling for a series of reforms to address what they see as structural imbalances in how LMArena operates. They argue that all tested model variants should remain visible on the platform, regardless of their performance.
In addition, they propose limiting how many versions a provider can submit at one time and ensuring fairer distribution of model exposure across users. The group also calls for clear documentation of model removals, including reasons for their withdrawal.
While acknowledging LMArena's growing influence in the AI ecosystem, the authors warn that without stricter oversight, the platform may end up rewarding strategic leaderboard optimization rather than actual performance improvements.
"The Arena is powerful, and its outsized influence demands scientific integrity," writes Sara Hooker, Head of Cohere Labs and one of the study's co-authors. Cohere — a Canadian company that develops AI models for enterprise use — may be disproportionately affected by platform dynamics that, according to the study, favor larger U.S.-based firms. Cohere led the research.
Former Tesla and OpenAI engineer Andrej Karpathy also expressed doubts about the benchmark's reliability. In a post on X, he described becoming "a bit suspicious" of the benchmark after noticing that a Gemini model ranked first on LMArena "way above the second best," despite underperforming in his own experience. Around the same time, he found Claude 3.5 to be one of the strongest models for everyday use, even though it ranked much lower on the platform.
He also pointed to other "relatively random models," often small and "with little to no real-world knowledge," that still appeared near the top of the leaderboard — raising further questions about whether the rankings truly reflect real-world model quality.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.