Popular LLM ranking platforms are statistically fragile, new study warns

Key Points
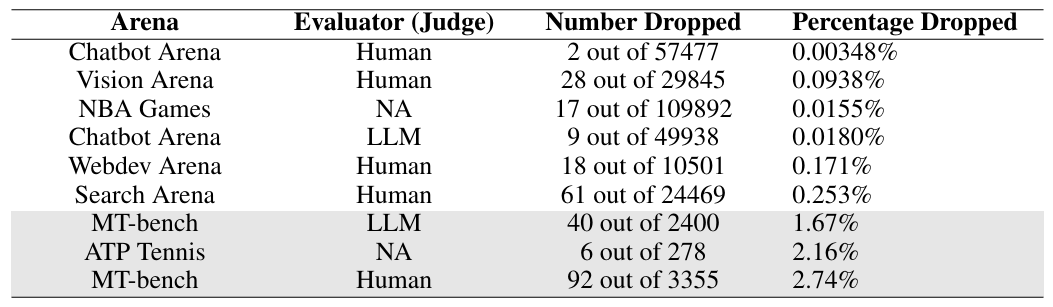
- Researchers at MIT and IBM Research have demonstrated that the rankings on popular LLM evaluation platforms like LMArena are highly fragile: removing just 2 out of 57,477 user reviews was enough to change which model held the top spot.
- This instability was consistent across nearly all platforms examined. The sole exception was MT-bench, where 2.74 percent of reviews needed to be removed to shift the ranking.
- To address the problem, the researchers recommend that platform operators screen ratings for outliers, ensuring that noise or individual user errors don't end up determining which model is ranked number one.
Researchers show that popular LLM ranking platforms are surprisingly fragile. Removing just 0.003 percent of user ratings is enough to topple the top-ranked model.
Unlike standardized benchmarks, platforms like Arena (formerly LMArena or Chatbot Arena) measure how language models perform in open-ended conversations with real users. These crowdsourced preference rankings carry serious weight: users rely on them to judge how helpful an LLM actually is, and companies use them to market their models.
But according to a study by researchers at MIT and IBM Research, these rankings are far less stable than they look. Removing just two user ratings out of 57,477 was enough to flip the number one spot.
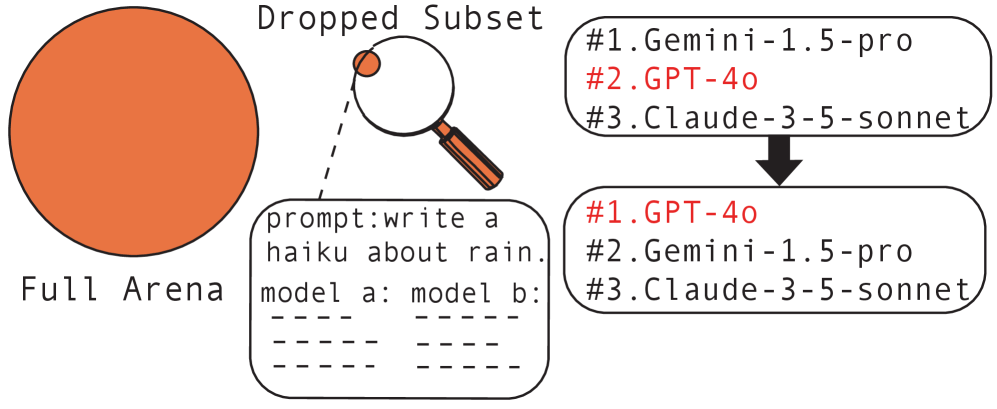
In this case, the top position shifted from GPT-4-0125-preview to GPT-4-1106-preview. The two removed reviews were matchups where GPT-4-0125-preview had lost to much lower-ranked models: Vicuna-13b at rank 43 and Stripedhyena-nous-7b at rank 45. A qualitative check using a strong judge model flagged both preferences as atypical judgments that strayed from what most users would pick.
"If it turns out the top-ranked LLM depends on only two or three pieces of user feedback out of tens of thousands, then one can’t assume the top-ranked LLM is going to be consistently outperforming all the other LLMs when it is deployed," says Tamara Broderick, professor at MIT and senior author of the study.
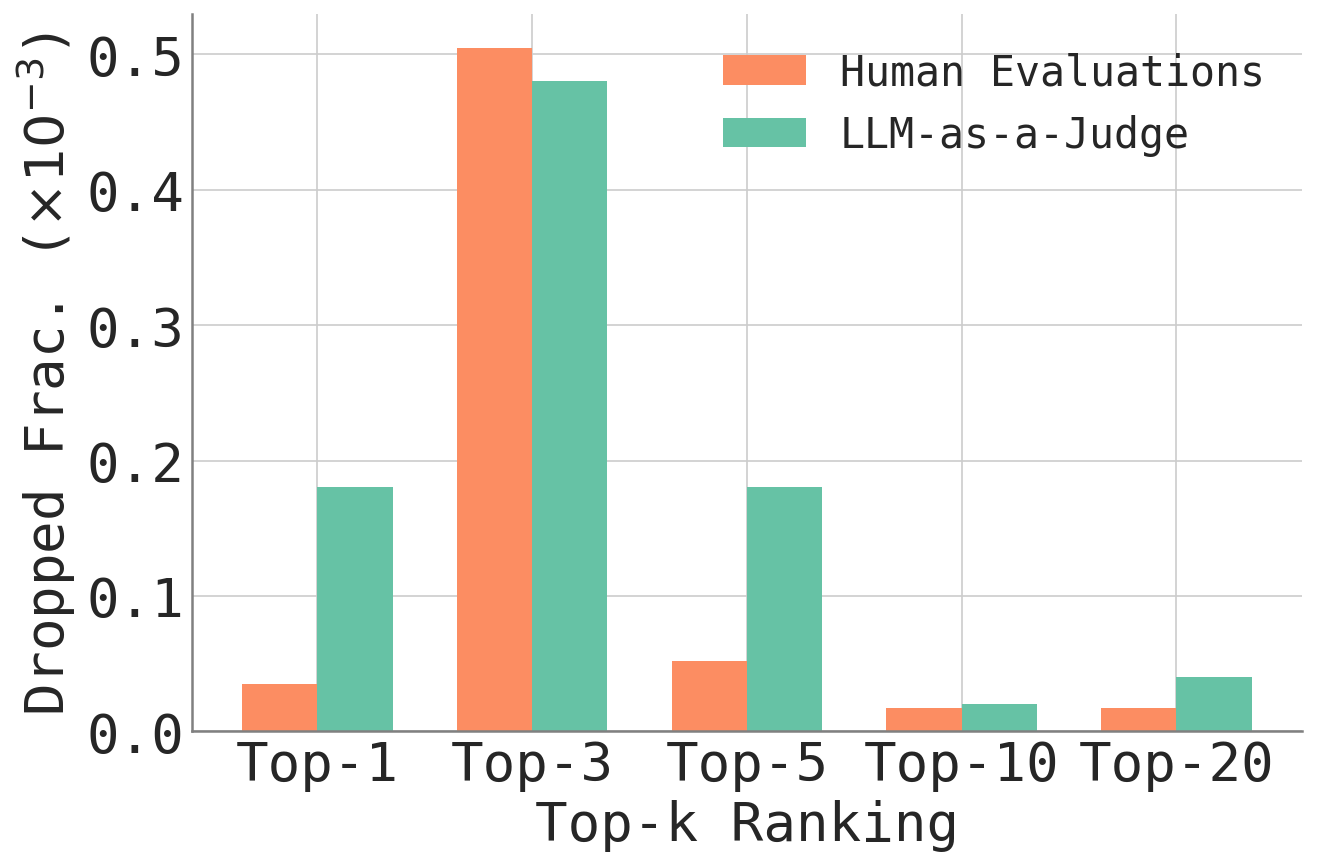
Beyond Chatbot Arena, the researchers also looked at Vision Arena, Search Arena, Webdev Arena, and MT-bench. The pattern held up everywhere: in Chatbot Arena with LLM judges, 9 out of 49,938 ratings (0.018 percent) flipped the top spot. In Vision Arena, it took 28 out of 29,845 (0.094 percent), and in Search Arena, 61 out of 24,469 (0.253 percent).
MT-bench was the only exception, requiring 92 out of 3,355 evaluations, about 2.74 percent. The researchers chalk up its higher robustness to design choices: MT-bench uses 80 carefully constructed multi-turn questions and relies on expert annotators instead of crowd ratings. The study found no clear evidence that human or AI-based evaluations are fundamentally more vulnerable than the other.
A fast approximation replaces brute-force search
Testing every possible combination of ratings to find the most influential ones would be computationally impossible. So the researchers built an approximation method that zeroes in on the data points whose removal would shift a ranking the most. Results are then verified through an exact recalculation without those data points. Analyzing a dataset of 50,000 ratings takes less than three minutes on a standard laptop, the researchers say.
The problem isn't unique to AI, either. In historical NBA data, removing just 17 out of 109,892 games (0.016 percent) was enough to change the top-ranked team. The researchers trace the issue to the underlying statistical method shared by both LLM platforms and sports ranking. It breaks down when performance gaps at the top are small.
Noise and user error could be driving the instability
Unlike previous work showing that Chatbot Arena could be gamed by injecting fake votes, this study focuses on the statistical robustness of existing data, not targeted attacks. The researchers suggest several fixes: letting users specify a confidence level with their preference, filtering out low-quality prompts, or having ratings reviewed by mediators.
"We can never know what was in the user’s mind at that time, but maybe they mis-clicked or weren’t paying attention," Broderick says. "The big takeaway here is that you don’t want noise, user error, or some outlier determining which is the top-ranked LLM."
The platform already faced heat in May 2025, when a study accused it of systematically favoring big providers like Meta and Google, partly because they could privately test numerous model variants ahead of time and only publicly list the best-performing versions. Their models also pulled in significantly more user ratings than those from smaller providers. The Arena operators pushed back on the accusations. In early January, the startup raised an additional $150 million and tripled its valuation to $1.7 billion.
The MIT and IBM Research study is yet another reminder that benchmarks and ranking platforms are, at best, a rough proxy for real-world AI performance. They're fragile and easy to distort—through user error, saturation effects, or targeted optimization on test tasks—yet they remain the best systematic comparison tool the industry has. If you want to know which model actually delivers, there's no substitute for hands-on testing with your own daily workflows.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now