Prompt engineering is "a bug, not a feature"

Logan Kilpatrick, OpenAI's developer relations manager, sees prompting as "a bug, not a feature."
Prompting as a skill is no different than the ability to communicate efficiently with humans, Kilpatrick says. The "heavy lifting" of crafting a prompt in detail is left to AI systems.
This, in turn, makes reading, writing, and speaking more important as human skills. Kilpatrick says that sometimes you can get five percent better performance with specific prompts.
In the future, however, the effort required to get good results will drop by a factor of 10, making special prompts no longer worthwhile.
Big AI is not leading the way
Kilpatrick's prediction stands in stark contrast to the way Big AI currently presents language models and their progress: Here, prompting strategies play a key role in achieving top scores on benchmarks.
For example, when Google introduced Gemini Ultra, it used a complex prompting process to achieve a new state-of-the-art score on the prestigious MMLU language comprehension benchmark.
Google then compared Gemini Ultra to GPT-4, but showed GPT-4's result with a less efficient prompting method, which earned the company some criticism. Using the same prompting method, Gemini Ultra ranked behind GPT-4 in MMLU.
Microsoft and OpenAI countered shortly thereafter with an even more complex prompt: Thanks to a modified version of the "Medprompt" developed for medical purposes, GPT-4 once again managed to outperform Gemini Ultra in the MMLU benchmark.
Beyond superficial PR, Medprompt itself is a prime example of the importance of good prompts: it improved the accuracy of GPT-4 in the MedQA dataset, which is about answering medical questions, to over 90 percent, with a performance improvement of about eight percent.
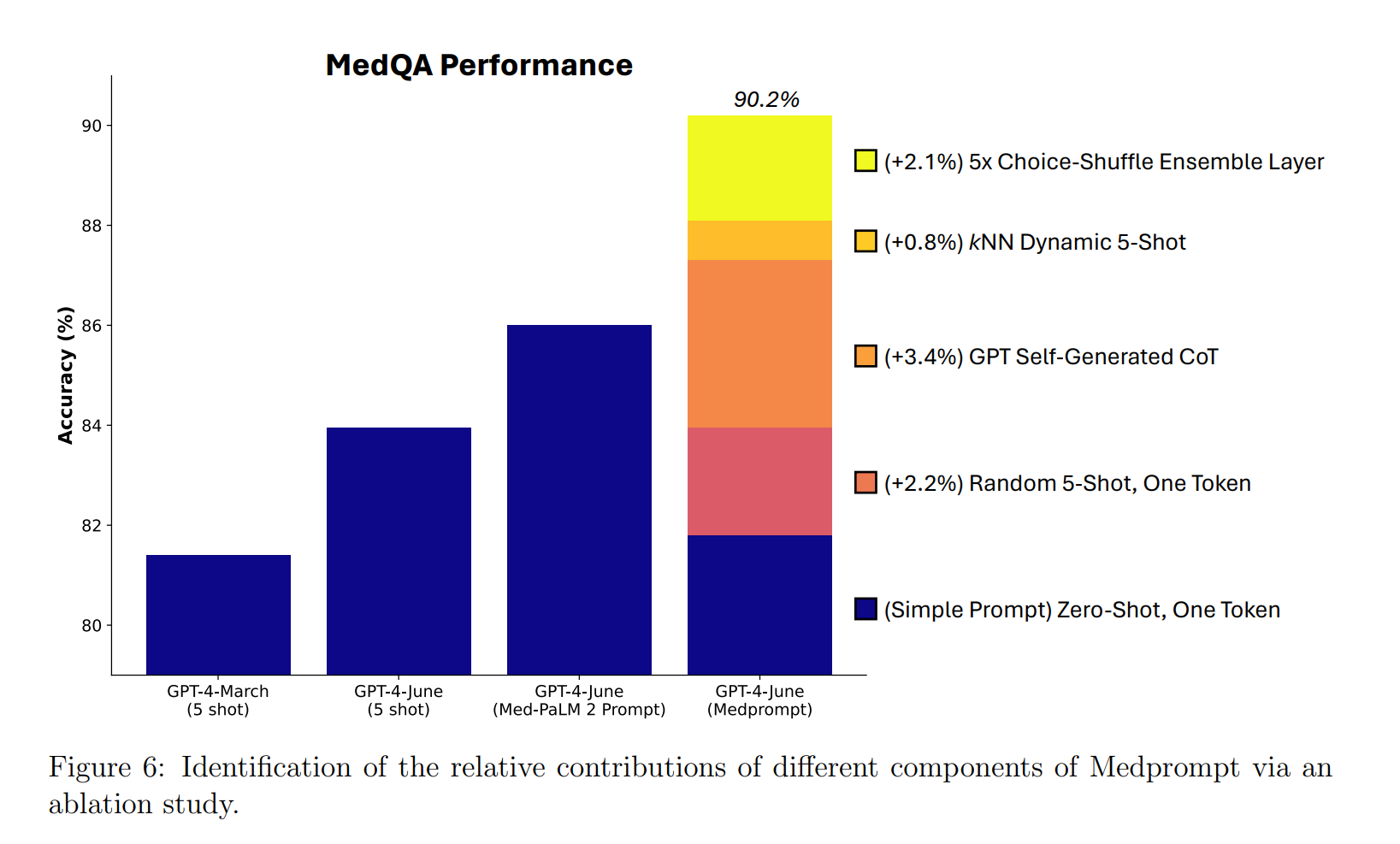
In practice, that eight percent can mean the difference between "unusable" and "usable" when it comes to accuracy in answering medical questions.
But, and this is the future scenario Kilpatrick describes, when GPT-5 and its ilk are well over 90 percent on a benchmark like MedQA anyway, a complex prompt like Medprompt will become less relevant, if not irrelevant.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.