Researchers combine two language models and a database for more accurate LLMs

Researchers have developed a new approach called "Speculative RAG" that combines two language models to make Retrieval Augmented Generation (RAG) systems more efficient and accurate.
RAG systems augment Large Language Models (LLMs) with external knowledge bases to reduce factual errors and bullshit, sorry, "hallucinations". However, RAG can still be prone to errors, especially with large amounts of data and complex contexts.
So developers are investigating how to improve RAG. One such approach is Speculative RAG. It aims to improve on traditional RAG systems by combining a smaller, specialized language model with a larger, general-purpose model.
A smaller "RAG Drafter" model generates multiple answer suggestions in parallel, based on different subsets of retrieved documents. This model is specifically trained on question-answer-document relationships. A larger "RAG Verifier" model then reviews these suggestions and selects the best answer.
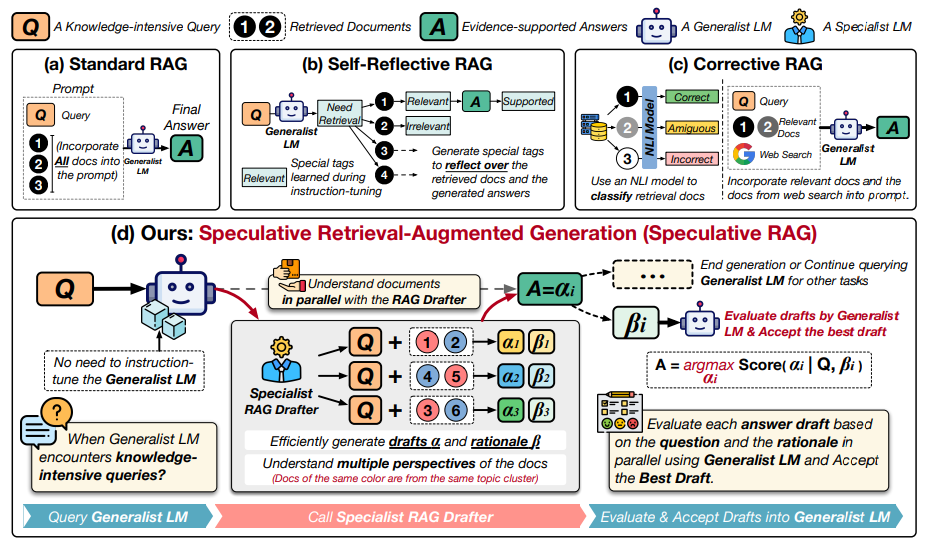
By generating answers from different document subsets in parallel, the specialized model produces high-quality options while processing fewer input tokens. The general model can then efficiently verify these suggestions without having to process lengthy contexts.
In tests on several benchmark datasets, the Speculative RAG framework achieved up to 12.97 percent higher accuracy with 51 percent lower latency compared to conventional RAG systems.
The University of California and Google researchers believe that splitting between specialized and general models is a promising approach to making RAG systems more efficient. "We demonstrate that a smaller, specialized RAG drafter can effectively augment a larger, general-purpose LM for knowledge-intensive tasks."
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.