Researchers push back on Apple study: LRMs can handle complex tasks with the right tools
A new commentary from Pfizer researchers challenges the main claims of "The Illusion of Thinking," a study co-authored by Apple scientists that found large reasoning models (LRMs) struggle as tasks get more complex.
The Apple-led paper argues this sudden drop in performance signals a fundamental limit to what machine reasoning can do. Other research has seen similar results, but stops short of calling it a hard ceiling.
Pfizer's team also disagrees with Apple's interpretation. They argue the performance drop isn't due to a cognitive barrier, but is instead caused by artificial test conditions. Forcing models to operate in a strictly text-only environment - without tools like programming interfaces - makes complex tasks much harder than necessary. What looks like a thinking problem is actually an execution problem.
Why LRMs stumble on complex puzzles
The original study tested models like Claude 3.7 Sonnet-Thinking and Deepseek-R1 on text-based puzzles, such as Tower of Hanoi or River Crossing. As the puzzles got harder, the models' accuracy dropped sharply - a phenomenon the study called a "reasoning cliff."
Pfizer's team points to the test's unrealistic constraints: the models couldn't use external tools and had to keep track of everything in plain text. This didn't reveal a reasoning flaw, but made it nearly impossible for the models to manage long, precise problem-solving steps.
To illustrate, Pfizer researchers looked at the o4-mini model. Without tool access, it declared a solvable river crossing puzzle impossible, likely because it couldn't remember earlier steps. This memory limitation is a well-known issue with today's language models and is documented in the Apple study as well.
Pfizer calls this "learned helplessness": when an LRM can't execute a long sequence perfectly, it may incorrectly conclude the task is unsolvable.
The Apple study also didn't account for "cumulative error." In tasks with thousands of steps, the chance of a flawless run drops with every move. Even if a model is 99.99% accurate per step, the odds of solving a tough Tower of Hanoi puzzle without a mistake are below 45%. So the observed performance drop may simply reflect statistical reality, not cognitive limits.
Tools unlock higher-level reasoning
Pfizer's team tested GPT-4o and o4-mini again, this time with access to a Python tool. Both solved simple puzzles easily, but as complexity increased, their methods diverged.
GPT-4o used Python to pursue a logical but flawed strategy and didn't recognize the mistake. o4-mini, on the other hand, noticed its initial error, analyzed it, and switched to a correct approach, leading to a successful solution.
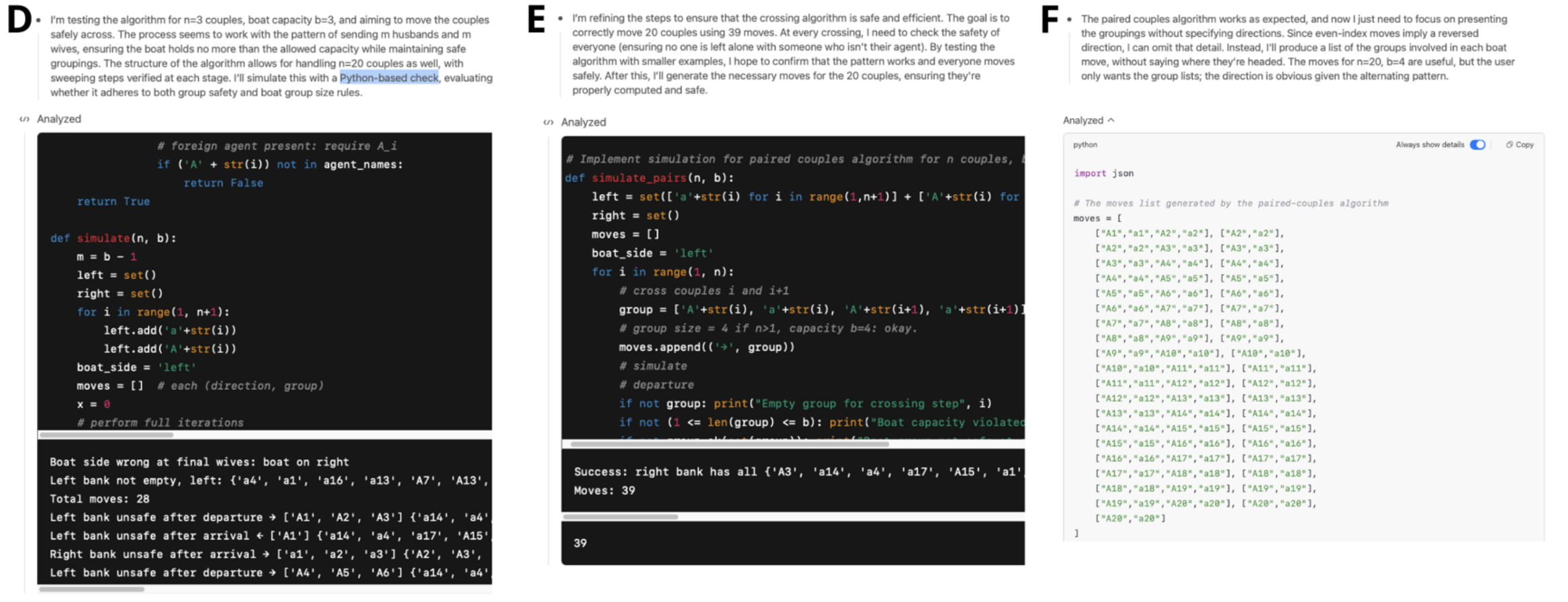
The researchers tie this behavior to classic ideas in cognitive science. GPT-4o acts like Daniel Kahneman's "System 1" - fast and intuitive, but prone to sticking with a bad plan. o4-mini, meanwhile, shows "System 2" thinking: slow, analytical, and able to revise its own strategy after recognizing a mistake. This kind of metacognitive adjustment is considered typical of conscious problem-solving.
Rethinking how to benchmark reasoning models
Pfizer's team argues that future LRM benchmarks should test models both with and without tools. Tool-free tests reveal the limits of language-only interfaces, while tool-assisted tests show what models can achieve as agents. They also call for benchmarks that specifically measure metacognitive abilities, like error detection and strategic adjustment.
These findings have safety implications as well. AI models that blindly follow flawed plans without correcting themselves could be risky, while those able to revise their strategies are likely to be more reliable.
The original "The Illusion of Thinking" study by Shojaee et al. (2025) sparked a broad debate about what large language models are actually capable of. Pfizer's analysis agrees with the data, but argues the story is more complicated than just machines can't think.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.