Stability AI's Stable Audio generates high-quality audio from simple text input

London-based startup Stability AI on Wednesday unveiled a new product called Stable Audio, which uses AI to generate custom music tracks and sound effects.
Stable Audio uses a diffusion-based AI model to create custom audio files in seconds from simple text input. Users specify genres, instruments, tuning, and other characteristics. The system then automatically composes matching songs, sound effects, or instrument stems.
Up to 90 seconds at 44.1 kHz
Stability AI tested the tool with inputs such as "Post-Rock, Guitars, Drum Kit, Bass, Strings, Euphoric, Up-Lifting, Moody, Flowing, Raw, Epic, Sentimental, 125 BPM". The result is a fast, atmospheric rock song at 125 BPM. According to Stability, this allows Stable Audio to create songs in a variety of genres, including ambient, techno, and trance.
Unlike previous AI-based music generators, Stable Audio seems to be able to produce musically coherent pieces in professional audio quality of 44.1 kHz over a longer period of up to 90 seconds.
The published samples sound authentic and hardly suggest that no human composers are behind it. On an Nvidia A100 GPU, 95 seconds of audio should be generated in less than a second, according to Stability AI.
The following sample songs and audio effects were generated using prompts such as "People talking in a crowded restaurant" or "Piano solo chord progression in major, upbeat 90 BPM".
You can listen to more Stable Audio demo songs here. Unfortunately, the servers are currently under heavy load, so you will need some luck to test the system yourself.
Artists get a share of the Stable Audio revenue
To achieve this quality, the system was trained on a music library provided by AudioSparx. AudioSparx partnered with Stability AI and promised the startup a cut of Stable Audio's revenue for using the approximately 800,000 songs, audio effects, and instrument snippets. In return, the creators of the songs used in the training can share in Stable Audio's profits through AudioSparx.
They were allegedly asked before the training if they wanted to make their songs available. This decision may be a response to the massive opposition Stability has faced in the copyright debate surrounding Stable Diffusion's training material.
According to Stability AI, users may use tracks created with Stable Audio for personal use free of charge. Commercial use requires a paid subscription. The company is targeting creative professionals, such as filmmakers or game developers, who need appropriate background music quickly.
Stability AI also plans to release an open-source music model trained on different datasets
Stable Audio differs from Stable Diffusion in that it is not open source, unlike the popular image model. However, the FAQ states that an open-source model trained on other data will be released soon.
The basis for Stable Audio is the text-to-music model Dance Diffusion, which was released by Harmonai in 2022 with support from Stability. However, Stable Audio is a model developed from scratch by the audio division of Stability Al, which was founded in April.
Using diffusion models for music is not a new idea. However, Stable Audio's strength lies in its ability to produce pieces of varying lengths, he said. This was taken into account during training, he said.
Stability AI explains the underlying technique this way:
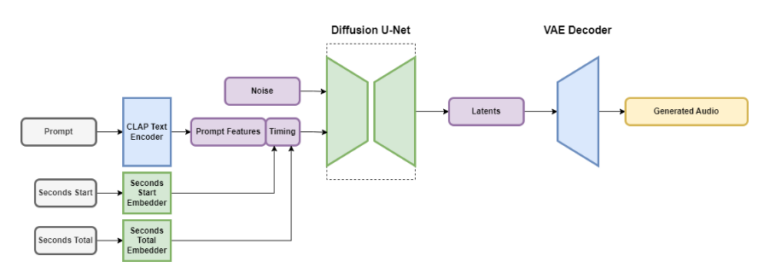
- Stable Audio is a latent diffusion model with several parts: a Variational Autoencoder (VAE), a text encoder, and a U-net-based diffusion model.
- The VAE compresses stereo audio into a lossy, noise-resistant, and invertible latent coding, allowing faster generation and training.
- A frozen text encoder of a newly trained CLAP model is used for text prompts.
- Timing embeddings are computed during training and used to control the output audio length.
- The diffusion model for Stable Audio is a 907 million parameter U-net based on the Moûsai model.
You can use Stable Audio exclusively through the recently launched web interface. 20 songs per month of up to 45 seconds are free for personal use. For $11.99 per month, you get 500 songs with up to 90 seconds of playback time and a commercial license.
No content filter could lead to easy plagiarism
The tool could also be used to fake songs by popular artists. So far, labels have been able to successfully fight such AI creations, but the legal situation is still unclear.
Stability AI itself insists in an interview with Techcrunch that it wants to use the technology responsibly. AudioSparx's database does not contain pop songs, but many that are labeled as such in the style of well-known artists. Unlike Google's MusicLM, the names of famous artists are not blocked, at least not yet.
It remains to be seen whether Stable Audio will pay off for Stability AI's business model, which has so far been in the red. In any case, the impressive quality of the AI compositions makes you sit up and take notice.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.