Stable Video 3D transforms a single image into near-perfect 3D views

With Stability AI's latest model, a single frame is all you need to generate near-perfect views of an object from multiple angles.
Stability AI has introduced Stable Video 3D (SV3D), a new generative model based on stable video diffusion. According to the company's blog post, SV3D is designed to significantly improve the quality, consistency, and controllability of generating 3D content from single frames.
SV3D comes in two flavors: SV3D_u generates orbital videos based on single-frame input with no specified camera control. The extended version SV3D_p supports both single frames and 3D objects as input, allowing the generation of videos along specified camera paths. However, the resolution of the resulting videos is still relatively low at 576 x 576 pixels at 21 frames per second.
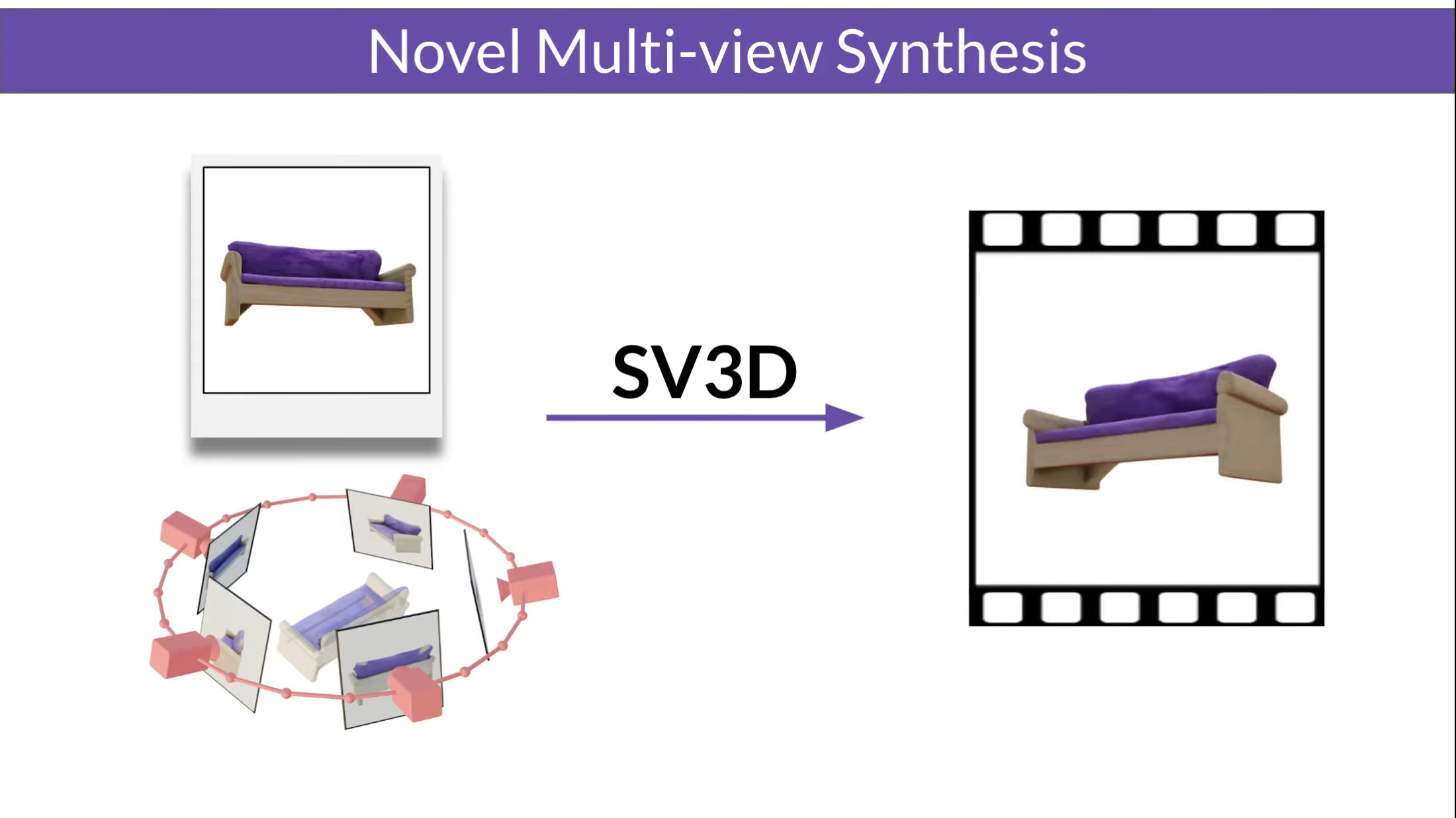
According to Stability AI, the use of video diffusion models, as opposed to image diffusion models such as those used in Stability AI's Zero123 released in December, offers great advantages in terms of generalization and view consistency of the generated output.
This is demonstrated in the following example, where SV3D generates detailed 3D views from a single photo compared to previous methods.

SV3D's processing pipeline is complex and includes the generation of Neural Radiance Fields (NeRF), which have led to major advances in 3D object generation in recent years. In addition, there is an illumination model that ensures the correct incidence of light depending on the viewing angle.
SV3D is now available for commercial use through the recently launched Stability AI membership. For non-commercial use, the model weights are available for download on Hugging Face.
SV3D appears to be a leap forward in creating consistent 3D views from single frames, which could benefit media creators in the fields of animation, game design, and VR.
The London-based AI startup has released several high-level visual models in recent months, including Stable Diffusion 3 for text-to-image, Stable 3D for text-to-3D, and Stable Video Diffusion for text-to-video.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.