Stable Video 4D creates moving 3D models from video

Stability AI has introduced Stable Video 4D, a new diffusion model that generates dynamic 3D content from a single video input. The technology combines two previous innovations.
Stable Video 4D builds on Stability AI's Stable Video 3D, released in March, which initially generated objects from images in new perspectives and created static 3D objects from them. Stable Video 4D advances this technology by producing moving 3D video content (also known as 4D) from a single, flat video input.
Video: Stability AI
The application aims to be user-friendly: Users can input a video, specify desired 3D camera positions, and Stable Video 4D quickly produces eight new videos that follow the specified camera views, providing a comprehensive view of the subject from multiple angles.
According to Stability AI, Stable Video 4D takes about 40 seconds to generate videos of 5 frames each across 8 views at 576 x 576 pixel resolution, with an additional 20 to 25 minutes for 4D optimization. While still time-consuming, this is significantly faster than previous methods that took hours.
Video: Stability AI
One of the key features of Stable Video 4D is its ability to generate multiple new videos simultaneously, ensuring a consistent object appearance across multiple views and timestamps. The researchers achieve this by combining a video and a multi-view diffusion model, in this case Stable Video Diffusion and Stable Video 3D. They say that this approach should work with any attention-based diffusion model.
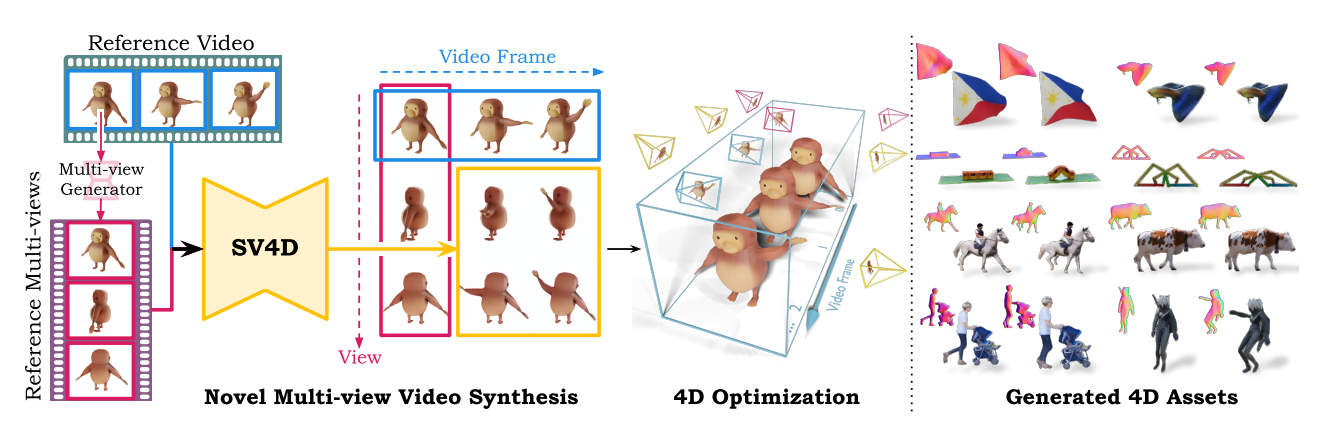
The researchers believe that the lack of a comprehensive training dataset has hindered the development of a powerful 4D model. To address this, they compiled ObjaverseDy, which they derived from the existing Objaverse dataset and filtered for suitable content. The SV4D model weights were initialized with the pre-trained SVD and SV3D weights, leveraging the prior knowledge learned from large video and 3D datasets.
In benchmarks with multiple datasets, SV4D outperformed existing methods in both novel view video synthesis and 4D optimization. The generated results showed superior visual quality, uniformity, and consistency across different perspectives compared to the previous state of the art. The differences between the methods in the following demo are particularly noticeable in examples such as the hiker's backpack and the cyclist.
Video: Stability AI
The company is working on refining the model so that it can process a wider range of real videos in addition to the synthetic datasets it is currently being trained on. Stability AI sees potential applications for Stable Video 4D in game development, video editing, and virtual reality.
Stable Video 4D is now available on Hugging Face and, given its slight quality advantage over alternative methods, likely represents the new state of the art in this area. However, its handling and resolution are still a long way from everyday use by game companies or film productions.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.