Study claims 78 training examples are enough to build autonomous agents

A new study challenges a core assumption in AI: instead of massive datasets, just 78 carefully chosen training examples may be enough to build superior autonomous agents.
Researchers from several Chinese institutions make this case in their LIMI ("Less Is More for Intelligent Agency") paper. They define "agency" as the ability of AI systems to act independently - discovering problems, forming hypotheses, and solving tasks through self-directed interaction with environments and tools.
LIMI flips the usual script for AI training. Instead of massive datasets, it uses just 78 handpicked examples from real software development and research tasks. Each one captures the full process of human-AI teamwork, from the first request through tool use, problem-solving, and final success. The goal: teach models to act as real autonomous agents.
On the AgencyBench benchmark, LIMI scored 73.5 percent using only 78 training samples. AgencyBench covers real-world scenarios such as building C++ chat apps, Java to-do lists, AI-powered games, microservice pipelines, and research tasks like LLM comparisons, data analysis, and business or sports analytics.
The performance gap is striking: Deepseek-V3.1 scored 11.9 percent, Kimi-K2-Instruct 24.1 percent, Qwen3-235B-A22B-Instruct 27.5 percent, and GLM-4.5 45.1 percent.
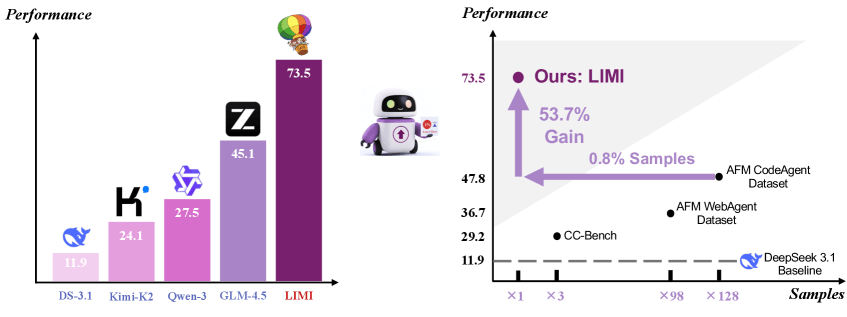
LIMI also nailed 71.7 percent of requirements on the first try, nearly doubling the best baseline. Its overall success rate was 74.6 percent, far ahead of GLM-4.5's 47.4 percent. On standard coding and scientific computing benchmarks, LIMI posted a 57.2 percent average, again leading all baselines. Alternative training approaches highlight the efficiency gap: for example, GLM-4.5 code, trained on 10,000 samples, reached only 47.8 percent on AgencyBench.
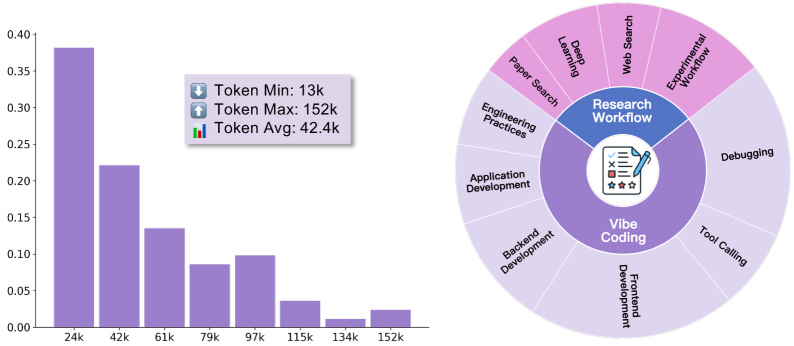
Some trajectories stretched to 152,000 tokens, highlighting the depth and complexity of the autonomous behaviors LIMI was able to learn.
Rethinking AI training methods
The LIMI approach works across different model sizes. LIMI-Air, with 106 billion parameters, improved from 17.0 percent to 34.3 percent; the larger LIMI, with 355 billion parameters, jumped from 45.1 percent to 73.5 percent.
The results could change how autonomous AI systems are developed. While traditional methods rely on ever-larger training pipelines and massive datasets, LIMI points toward a different path. This approach looks promising, but it will need more research and real-world testing before it can become the new standard. The code, models, and datasets are all public.
Nvidia researchers have recently argued that most AI agents use language models that are far too large, and that models under 10 billion parameters may be sufficient for agentic tasks. LIMI's results back this up, offering empirical evidence that careful data curation can beat brute-force scaling.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.