Study maps developer frustration over "AI slop" as a "tragedy of the commons" in software development

A qualitative study looks at how developers perceive and push back against low-quality AI content, or "slop," in software development. The critics describe a "tragedy of the commons" where individual productivity gains come at the cost of reviewers and the open-source community.
In a qualitative study, researchers from Heidelberg University, the University of Melbourne, and Singapore Management University looked at how developers who see AI content as a problem justify and structure their criticism. Sebastian Baltes, Marc Cheong, and Christoph Treude analyzed 1,154 posts from 15 discussion threads on Reddit and Hacker News.
The researchers specifically searched for threads containing the term "AI slop." That means the dataset skews heavily toward developers who already view the phenomenon negatively. Positive or neutral experiences with AI-assisted code generation are largely absent by design. So the study doesn't represent the broader developer community's opinion on AI tools, but it maps the arguments of a critical subgroup.
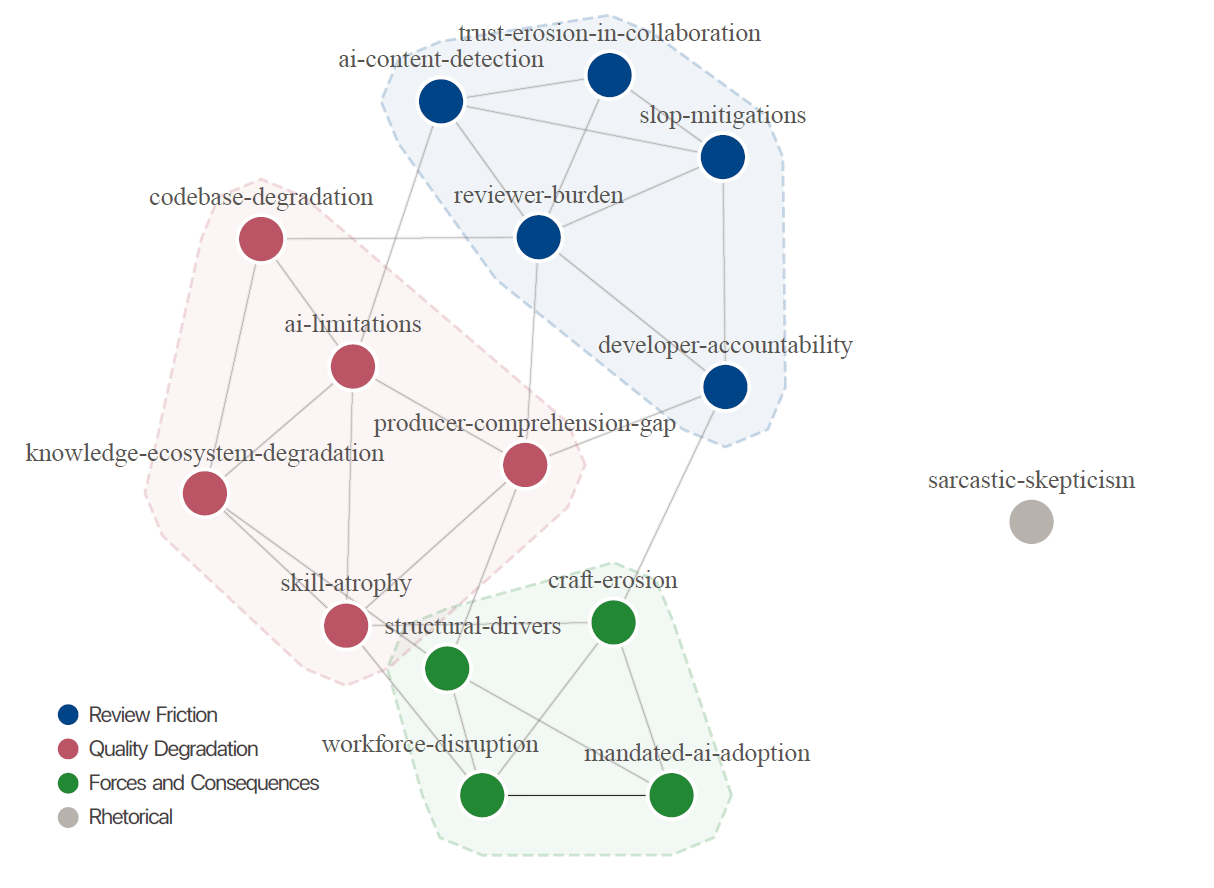
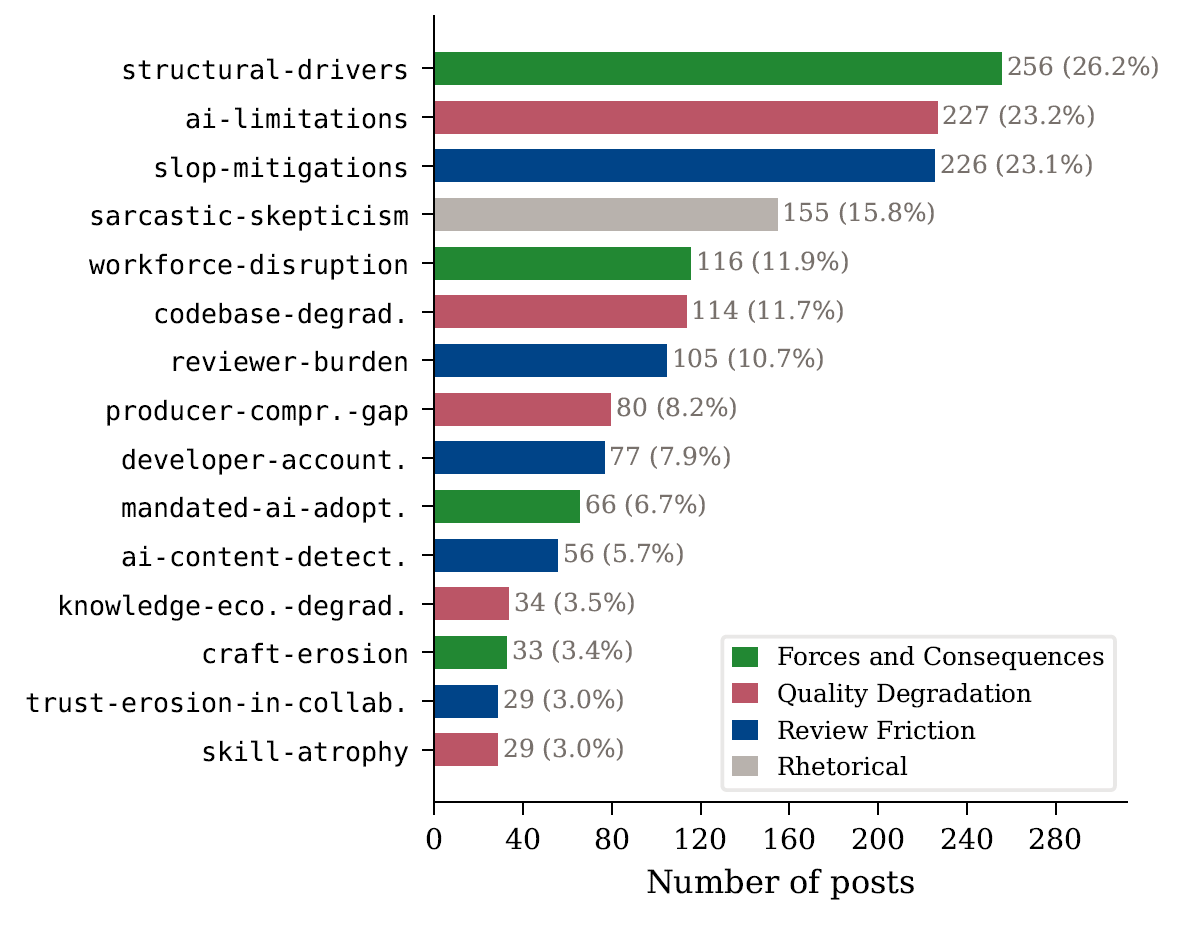
Using this data, the researchers developed a codebook with 15 categories across three thematic clusters: Review Friction, Quality Degradation, and Forces and Consequences.
Proponents of AI-assisted development would likely push back on this frustration by arguing that human-perceived code quality matters less as AI improves. One OpenAI employee, for example, predicts that AI-generated code will soon stop being reviewed manually, leading to "system failures that will be harder to debug than most," but ones that will ultimately get resolved. Well-known AI developer Andrej Karpathy has already called humans the bottleneck in AI-assisted research.
Follow that logic far enough, and the human bottleneck only gets worse as models get better. The question then isn't whether code meets human quality standards, but whether it works and can be maintained, iterated, and optimized by AI agents. In this vision, humans supervise the process without checking every line by hand.
Individual productivity gains, collective costs
The study's central finding paints a different picture: the critical developers describe AI slop as a tragedy of the commons. Individual developers and companies reap the benefits of AI-generated output, but reviewers, maintainers, and the broader community end up footing the bill. Codebases accumulate technical debt, knowledge resources get polluted, reviewers burn out, and the trust that holds collaborative development together breaks down.
The problem hits especially hard in the open-source world, where shared resources are maintained by volunteers. Real-world cases already illustrate this: the curl project shut down its bug bounty program after AI-generated vulnerability reports ate up maintainer time without producing valid results. Apache Log4j 2 and the Godot game engine reported similar issues.
Developers also reported having AI workflows forced on them by management. In one case, C-level executives copied AI output directly in response to every technical problem the team ran into.
Reviewers turned into unpaid prompt engineers
A dominant theme among the critical voices was the burden placed on people who have to review AI-generated code. "The development time has been shortened but the team now needs to spend more time to review. Doesn't look like any benefit," one developer said. One team reported 30 pull requests per day with just six reviewers.
Reviewers described the feeling of being "the first human being to ever lay eyes on this code" and complained about being turned into unpaid prompt engineers: "They're literally just using you to do their job (i.e., critically evaluate and understand their AI slop and give it the next prompt."
Reviewers also developed their own heuristics for spotting AI-generated code. Emojis in code comments are considered a near-certain giveaway. Other markers include step-by-step comment patterns, bloated style, and Unicode artifacts. Trust in collaborative processes also takes a hit. One developer described an AI agent's pull request: "I don't know how you could trust any of it at some point. No real understanding of what it's doing, it's just guessing."
AI agents also exhibited troubling behavior, according to the reports. The study describes "death loops" of self-consciously incorrect corrections and cases where agents changed tests so that broken code would pass instead of fixing the actual code. In one case, an AI agent "hallucinated external services, then mocked out the hallucinated external services," creating an internally consistent but completely fictitious integration.
Beyond codebases, some developers described a degradation of external knowledge resources. "I'm starting to see documentation and tutorials missing key information and code samples needed to be able to implement something now. Or it's just completely wrong or using a class that doesn't exist."
The study also identified concerns about collective skill atrophy. One Hacker News commenter described a Catch-22: if you need to be an experienced engineer to use AI effectively, but you had to become experienced without AI, how are new experienced engineers supposed to emerge? This concern applies to large parts of knowledge work.
Countermeasures range from PR limits to accountability standards
The study documents specific counter-strategies that developers are proposing or already putting into practice: size limits for pull requests with AI-generated code ("less than 500 LOC per PR or they won't review it"), mandatory self-reviews before peer review, synchronous code walkthroughs, double code reviews with external teams, and tying accountability to performance reviews.
The researchers draw recommendations for three groups from their findings. Tool developers should shift their focus from code generation to verification and review—for example, through uncertainty indicators and provenance information. Tools should also encourage smaller, incremental changes and structure their output so it's easier to inspect.
Team leaders should rethink evaluation criteria that reward output volume and instead account for downstream costs like review effort and error rates. At the same time, the study emphasizes that developers should keep control over when and how they use AI tools. Teams should also require contributors to understand and explain their changes, backed by practices like PR size limits and code walkthroughs.
For educational institutions, the researchers recommend exam formats like oral exams or live coding, along with limiting AI tool use in early coursework so students build foundational skills first. Working output alone isn't proof of competence, they say.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.