Together AI releases open deep research tool for structured web queries

Together AI has introduced Open Deep Research, an open-source tool designed to answer complex questions through structured, multi-step web research.
The framework is based on a concept originally introduced by OpenAI but takes a more transparent approach: its code, datasets, and system architecture are fully open to the public.
Unlike conventional search engines that return a list of links requiring users to extract relevant information themselves, Open Deep Research generates structured reports with citations. According to Together AI, the system is “designed to deliver structured reports with citations,” as described in a company blog post.
Other companies have launched similar tools. Google, Grok, and Perplexity all offer deep research-style functionality. Anthropic recently introduced an agent-based research feature for its Claude model. Shortly after OpenAI’s system was released, Hugging Face announced its own open-source alternative but has not continued development.
Planning, searching, reflecting, writing
Open Deep Research uses a four-step process. A planning model first generates a list of relevant queries, which are then used to collect content via Tavily’s search API. A verification model checks for gaps in knowledge, followed by a writing model that compiles the final report.
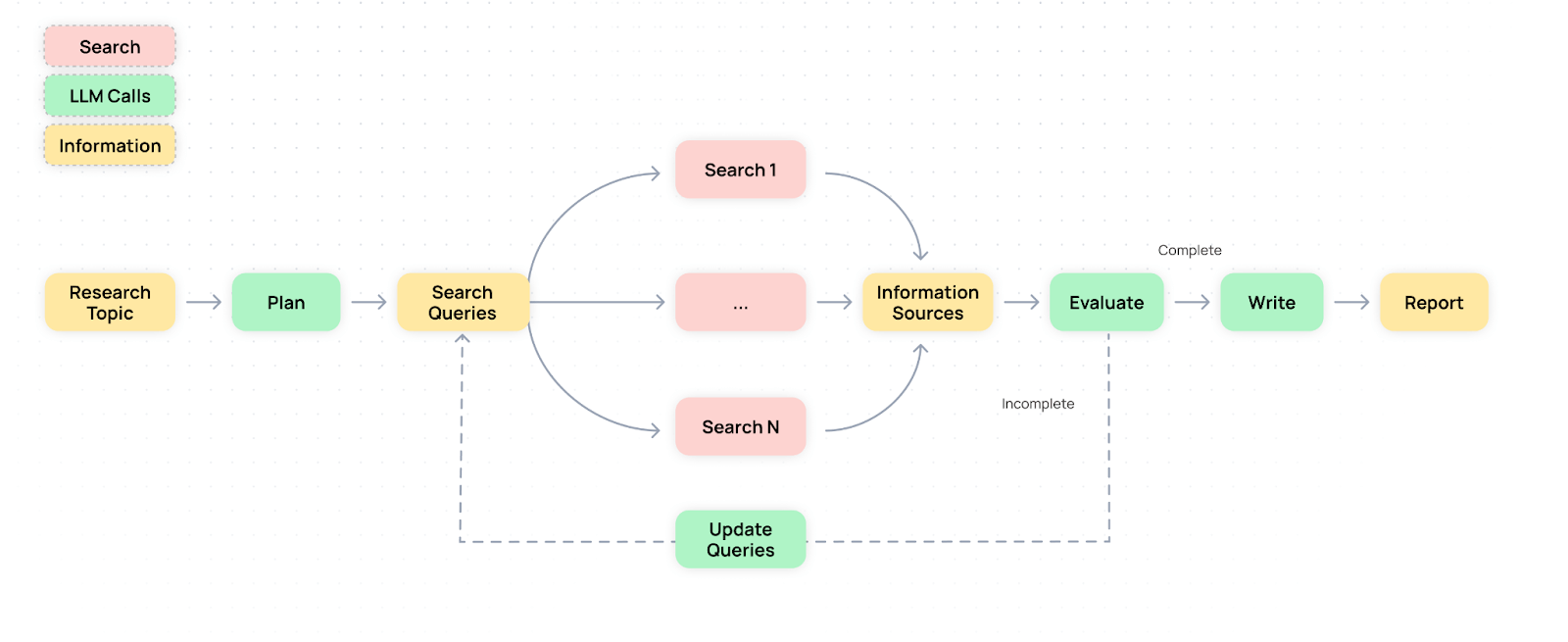
To handle long documents, an additional summarization model condenses the content and evaluates its relevance. This step is intended to prevent large language models from exceeding their context window limits.
The system architecture incorporates specialized models from Alibaba, Meta, and DeepSeek. Qwen2.5-72B handles the planning stage, while Llama-3.3-70B summarizes content. Llama-3.1-70B extracts structured data, and DeepSeek-V3 writes the final report. All components are hosted on Together AI’s private cloud infrastructure.
Multimodal outputs and podcast functionality
Final outputs are formatted in HTML and include both text and visual elements. The system uses the Mermaid JS JavaScript library to generate charts, and creates automatic cover images using Flux models from Black Forest Labs.
The results can also be output as a podcast. | Video: Together AI
The platform also supports a podcast mode that summarizes the report’s content. This feature is powered by Cartesia’s Sonic voice models.
Benchmarks show benefits of multi-step retrieval
Performance was evaluated using three benchmarks: FRAMES (multi-step reasoning), SimpleQA (factual knowledge), and HotPotQA (multi-hop questions). In all three cases, Open Deep Research outperformed base models that do not use search tools. The system also showed higher answer quality than LangChain’s Open Deep Research (LDR) and Hugging Face’s SmolAgents (SearchCodeAgent).
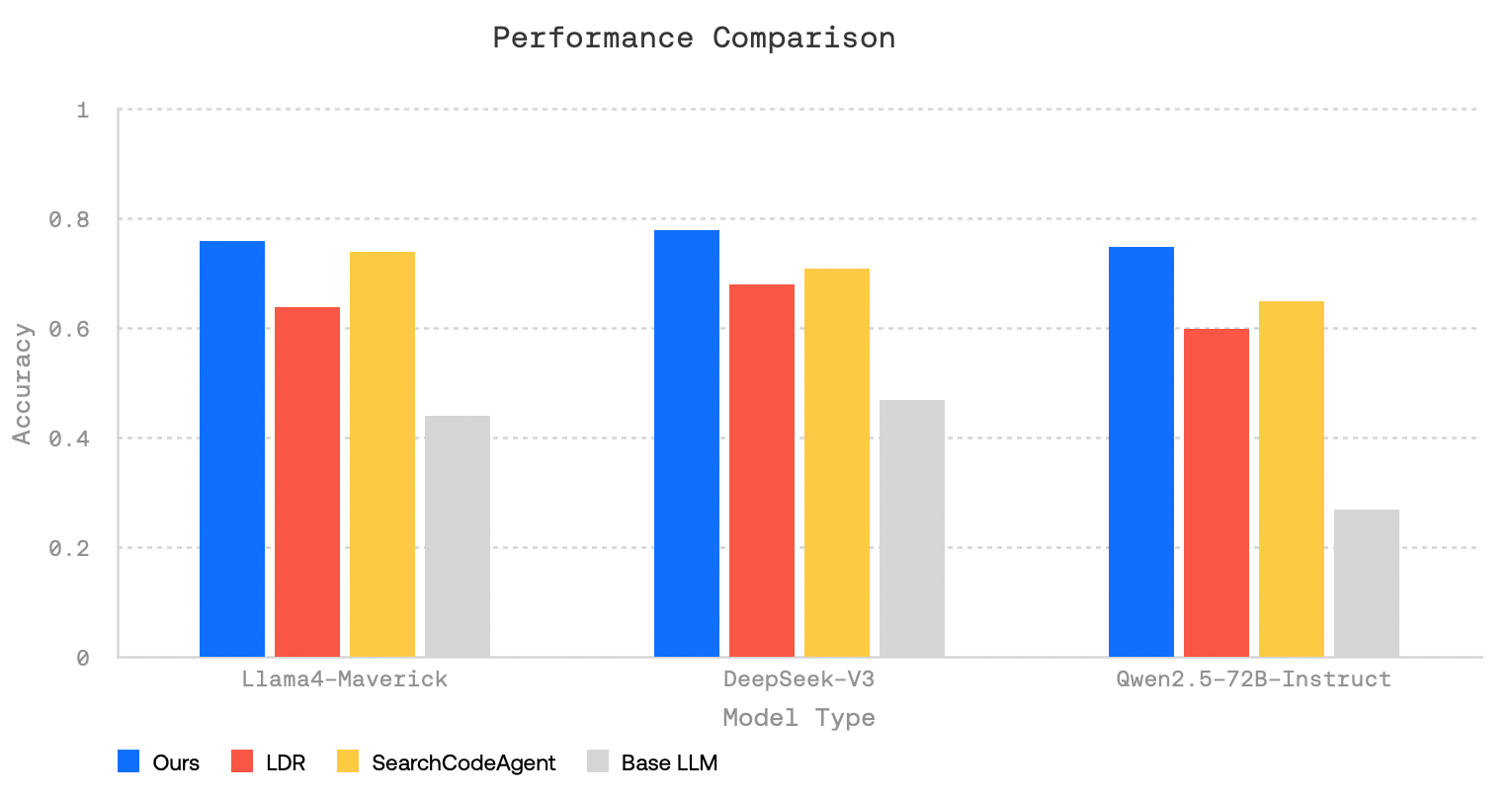
According to test results, multiple rounds of research significantly improved accuracy. When the system was limited to a single search iteration, performance declined.
Known limitations: hallucinations, bias, outdated data
Despite improvements, some fundamental weaknesses remain. As Together AI notes, “errors in early steps can propagate through the pipeline.” The system is also susceptible to hallucinations, particularly when interpreting ambiguous or contradictory sources.
Structural bias in training data or search indices may also affect results. Topics with limited coverage or that require real-time information—such as live events—are especially vulnerable. While caching can reduce costs, Together AI warns that it can lead to outdated information being delivered if no expiration policy is set.
Open platform for research and development
Together AI says the release is intended to create an open foundation for further experimentation and improvement. The architecture is designed to be modular and extensible, allowing developers to integrate their own models, customize data sources, or add new output formats. All code and documentation are publicly available via GitHub.
The company previously released an open-source code model that approaches the performance level of OpenAI’s o3-mini, but with significantly fewer parameters.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.