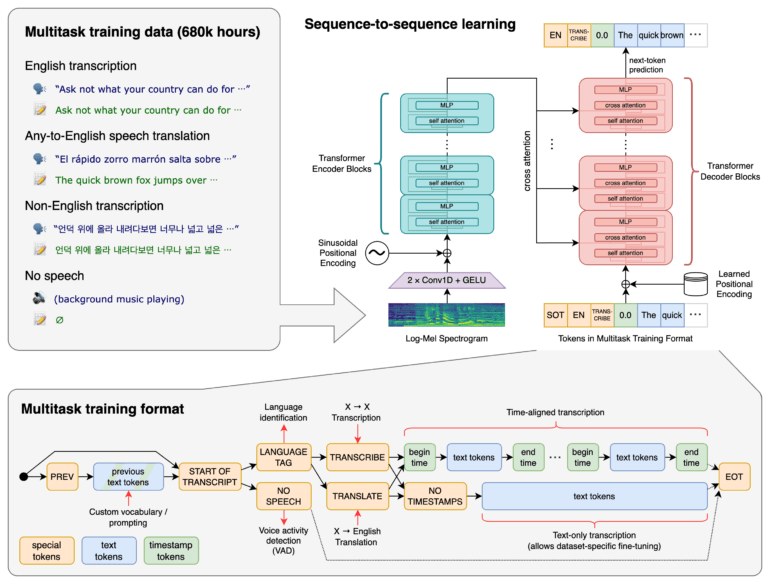
OpenAI's new open-source model "Whisper" can transcribe many languages and serve as the basis for audio applications.
Whisper has been trained with 680,000 hours of audio and multitasking data (e.g., transcription, translation, background music, etc.). The Transformer-based model proves that this extensive data training makes speech recognition more robust to accents, background noise, and technical speech, according to OpenAI.
Whisper supports recognition, transcription, and translation in different languages, as well as the identification of a language. In English, which accounted for about two-thirds of the training dataset, Whipser's speech recognition capability is said to approach human levels.
Whisper, a neural net that approaches human level robustness and accuracy on English speech recognition. Attached is transcriptions of the same voicemail with iOS vs Whisper. Available today as open-source: https://t.co/fyHWviSfa4 pic.twitter.com/jgNAsBkB2H
— Greg Brockman (@gdb) September 21, 2022
OpenAI highlights zero-shot capability
In the LibriSpeech speech recognition benchmark, Whisper does not match the performance of smaller, specialized AI speech models, such as those trained with audio-text pairs specifically for that benchmark.
However, OpenAI highlights Whisper's zero-shot capability without prior fine-tuning, thanks to which the model has a 50 percent lower error rate than previously mentioned systems when tested across many data sets. Whisper is "much more robust" than LibriSpeech-focused speech recognition models, according to OpenAI.
These measurements apply to English speech recognition. The error rate increases for languages underrepresented in the dataset. In addition, OpenAI warns that Whisper may transcribe words that were not spoken: The company attributes this to noisy audio included in the data training.
Whisper can serve as a foundation for real-time transcription apps
OpenAI makes Whisper available for free on Github as an open-source model. The company says it is releasing Whisper primarily for research and as a basis for future work on better speech recognition.
According to OpenAI, the Whisper models cannot be readily used for speech recognition applications. But the speed and scale of the models likely made it possible to develop applications that provide real-time speech recognition and translation. Whisper's speed and accuracy are the basis for applications for affordable automatic transcription and translation of large amounts of audio data, OpenAI said.
It is possible that OpenAI will also use Whisper for its own purposes: The company needs large amounts of text for training language models such as GPT-3 and, soon, GPT-4. By automatically transcribing audio files, OpenAI would have access to even more text data.





