Language models are a poor choice for answering financial questions, study says

Are large language models fit for the financial world? A new study shows that even the best LLMs struggle to correctly answer questions about financial data.
Researchers at Patronus AI have found that large language models, such as OpenAI's GPT-4 Turbo or Claude 2, often fail to answer questions about SEC filings. This underscores the challenges that regulated industries such as finance face when implementing AI models in customer service or research processes.
Poor accuracy across all models tested
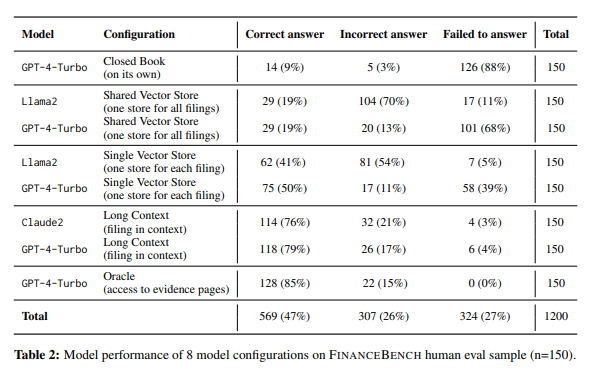
Patronus AI tested four language models for answering questions about corporate financial reports: OpenAI's GPT-4 and GPT-4 Turbo, Anthropics Claude 2, and Metas Llama 2. The best model, GPT-4 Turbo, achieved only 79 percent accuracy in Patronus AI's test, even though almost the entire report was included in the prompt.
The models often refused to answer questions or made up facts and figures that were not included in the SEC filings. According to Anand Kannappan, co-founder of Patronus AI, this performance is unacceptable and should be much higher for use in automated and production-ready applications.
FinanceBench tests 10,000 financial questions
Patronus AI developed FinanceBench for the test, a dataset of more than 10,000 questions and answers from SEC filings of major public companies. The dataset includes the correct answers and their exact location in the reports. Some answers require simple mathematical or logical reasoning.
Has CVS Health paid dividends to common shareholders in Q2 of FY2022?
Did AMD report customer concentration in FY22?
What is Coca Cola’s FY2021 COGS % margin? Calculate what was asked by utilizing the line items clearly shown in the income statement.
Questions from FinanceBench
The researchers believe that AI models have significant potential to assist the financial sector if they continue to improve. However, current performance levels show that humans still need to be involved in the workflow to support and manage the process.
One possible solution could be to make AI systems more familiar with the specific task through improved prompting. This could increase their ability to extract relevant information. However, the question remains whether such approaches can solve the problem in general or only in certain scenarios.
In its usage guidelines, OpenAI rules out using an OpenAI model to provide individual financial advice without a qualified person reviewing the information.
Known problem with no new solution
Language models with large context windows are known to have difficulty extracting information reliably, especially from the middle of long texts. This phenomenon, known as "lost in the middle", raises questions about the usefulness of large context windows for LLMs.
Anthropic has recently developed a method to solve the "lost in the middle" problem of its Claude 2.1 AI model by prefacing the model's answer with the sentence "This is the most relevant sentence in the context:". Tests need to show whether this method scales reliably to many tasks and provides a similar improvement for other LLMs such as GPT-4 (Turbo).
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.