
OpenAI's GPT-4 Turbo can process 16 times more tokens simultaneously than the original GPT-4 in ChatGPT. This feature comes with a big "but" though.
GPT-4 Turbo can process up to 100,000 words (128,000 tokens) or 300 pages of a standard book at once. The previous GPT-4 model in ChatGPT could only handle 8,000 tokens, which is about 4,000 to 6,000 words.
Thanks to the much larger context window, GPT-4 Turbo can process much more content and answer detailed questions about it or summarize it. While this is true, initial tests also indicate that you should not rely on this ability.
In late July, researchers at Stanford University, the University of California, Berkeley, and Samaya AI demonstrated for the first time that large language models are particularly good at retrieving information at the beginning and end of a document.
However, content in the middle tends to be overlooked, an effect that is amplified when the models process a lot of input at the same time. The researchers dubbed this effect "Lost in the Middle."
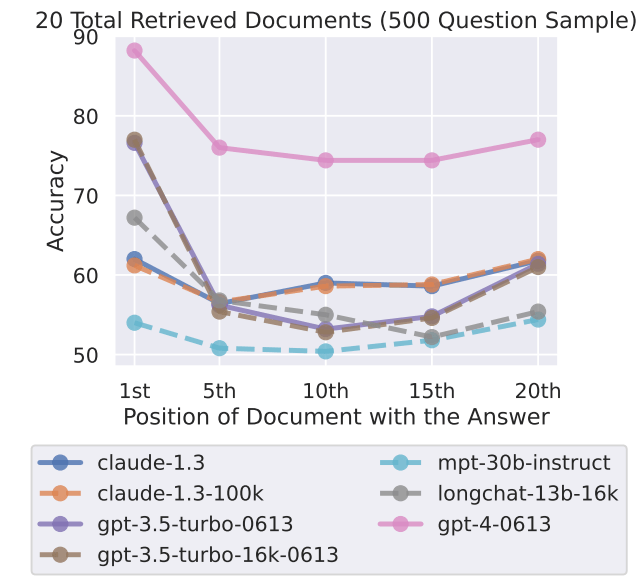
GPT-4-Turbo also misses facts in the middle and at the end of large inputs
Inspired by this research, Greg Kamradt, Shawn Wang, and Jerry Liu have now conducted initial tests to see if this phenomenon also occurs with GPT-4 Turbo. In his presentation of GPT-4 Turbo, OpenAI CEO Sam Altman emphasized the accuracy of the new model in large contexts.
Kamradt's testing method consisted of loading essays by Paul Graham into the system and placing a random statement ("The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day") at various points in the document.
He then tried to extract this information and had another instance of GPT-4 evaluate how well this worked.
In his analysis, Kamradt found that GPT-4's recall decreased above 73,000 tokens and correlated with the low recall of the statement, which was located between 7 percent and 50 percent of the document depth. However, if the statement was at the beginning of the document, it was found regardless of context length.

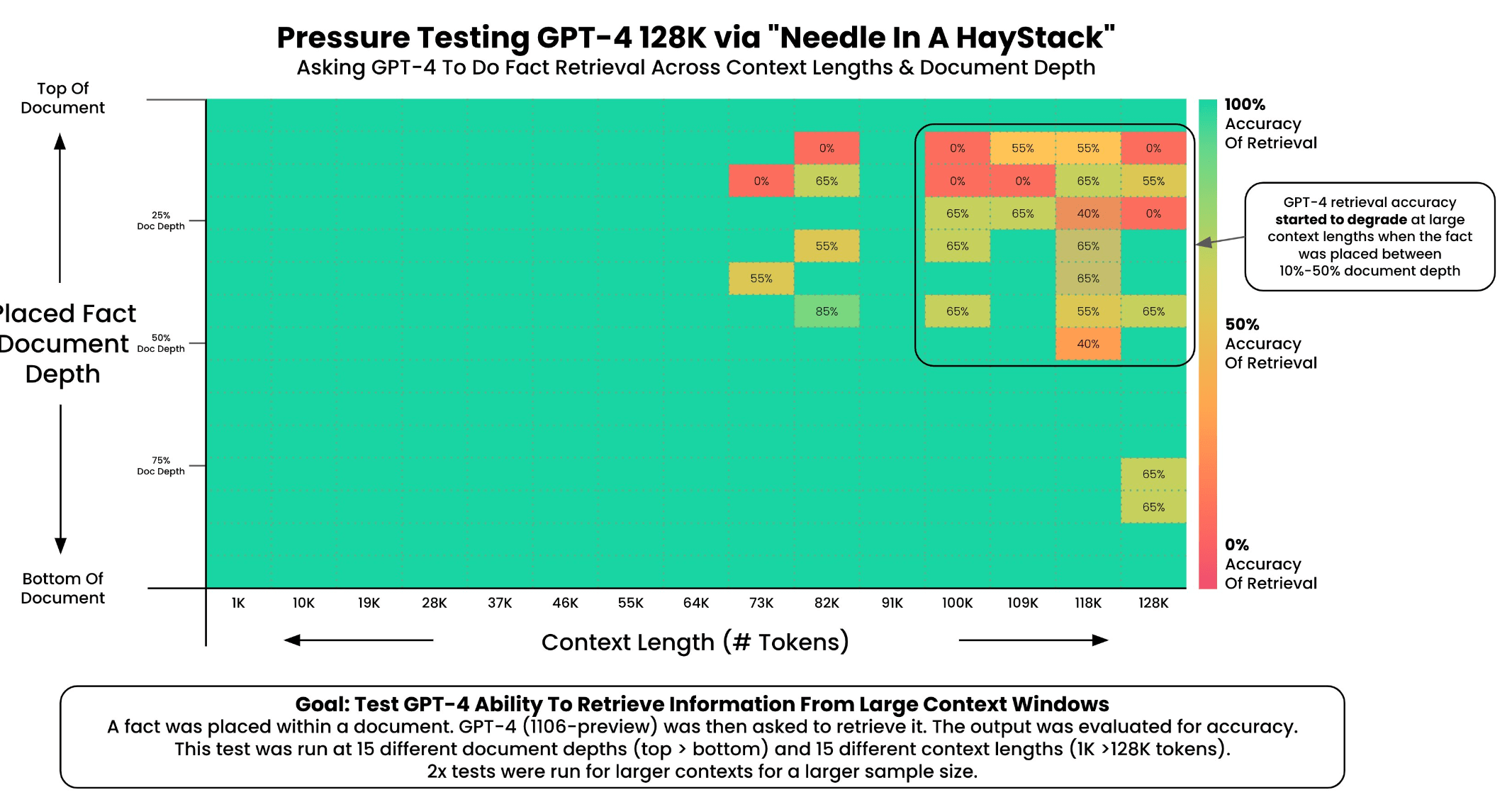
Wang's test showed that although GPT-4 Turbo was able to retrieve 3.5 times more accurate information than the previous GPT-4 with 16,000 tokens, it also showed that the reliability of information retrieval is particularly high at the beginning of the document and then declines sharply.
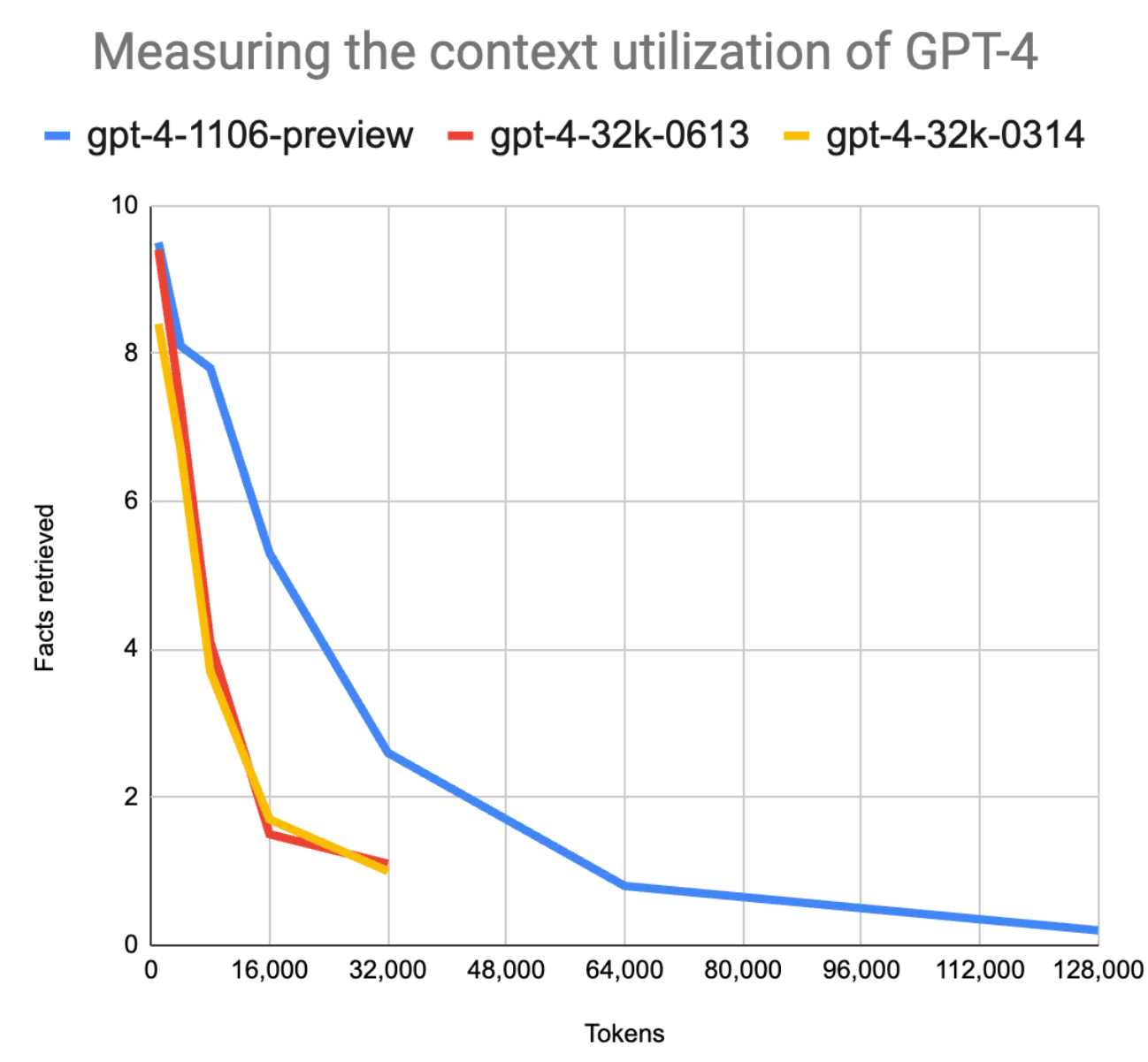

Liu studied GPT-4 Turbo and Claude-2 for extracting information from large documents (>= 250,000 tokens). He also concluded that there are still problems with summarizing and analyzing large documents. However, GPT-4 Turbo with 128,000 tokens performed significantly better than Claude 2 with 100,000 tokens, especially when Liu used a step-by-step approach for GPT-4 Turbo.
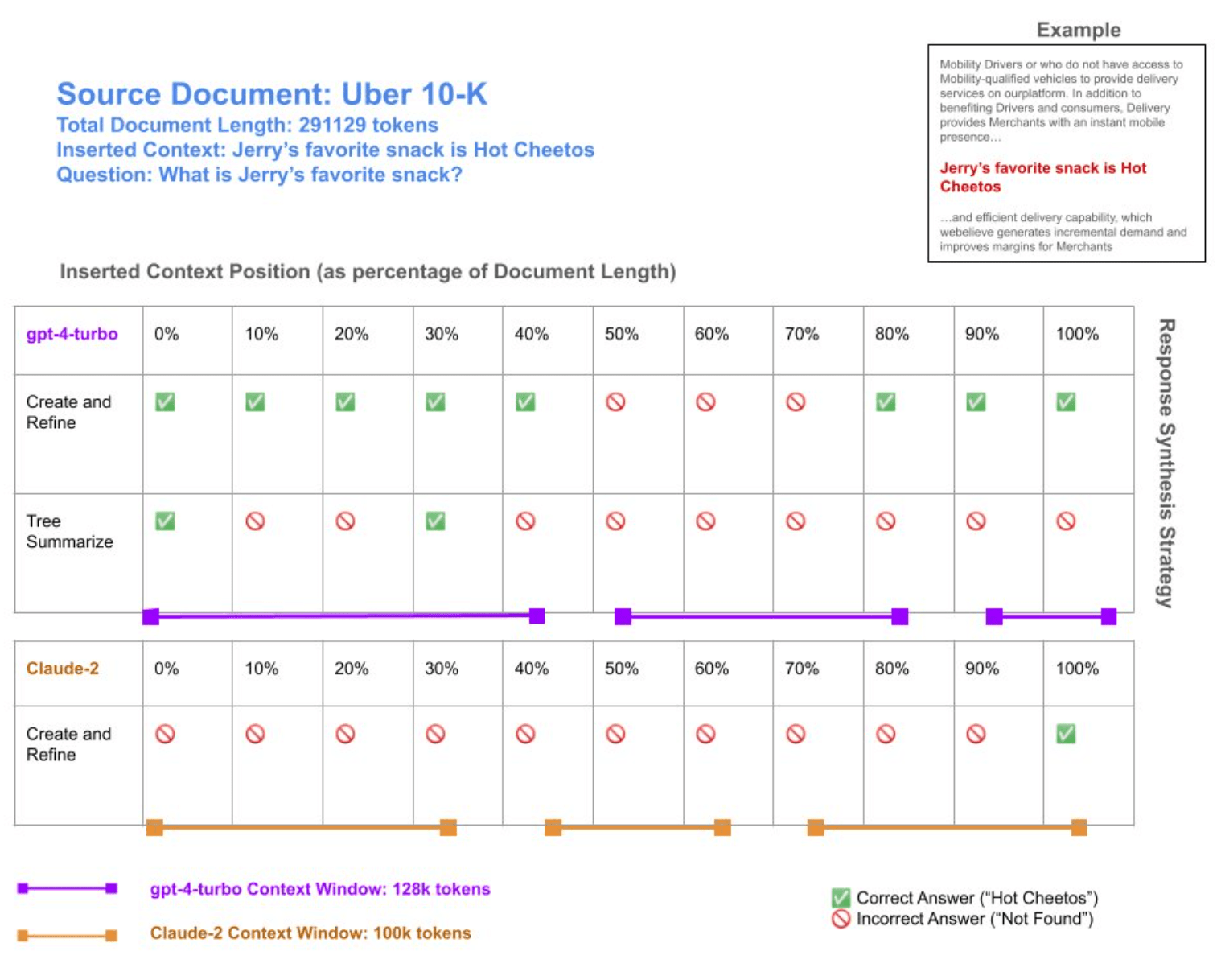
The key takeaways for users from these tests are that facts in large documents are not guaranteed to be retrieved, that reducing the context can increase accuracy, and that position is important for information retrieval.
Information retrieval is more reliable with a vector database
All three tests are not yet statistically significant. However, they clearly show that OpenAI has improved the problem of large context windows, even if it is not yet solved. There are several ways to increase the size of the context window, and we do not know which one OpenAI used. Simply scaling it up would not be sufficient, as the computations required would increase by a square factor.
Thus, the benefit of a large context window is not as obvious as it may seem at first glance, and the unreliability of the information in the middle may actually prove to be a hurdle in real-world applications.
Therefore, embedded search functions or vector databases still have their place despite large context windows, as they are more accurate and less expensive when searching for specific information. The computation of models with large context windows is significantly more expensive than the inference of models with small context windows.




