How DeepMind's Genie AI could reshape robotics by generating interactive worlds from images
Researchers at DeepMind have developed Genie, a model that creates worlds from images and moves video game characters around in them on their own. It sounds like a gimmick, but it could be the basis for something much bigger.
"What if, given a large corpus of videos from the Internet, we could not only train models capable of generating novel images or videos, but entire interactive experiences?" That's the question researchers at Google DeepMind asked themselves as they developed their new AI model, Genie (Generative Interactive Environments).
Video: Google DeepMind
Genie can transform various types of image prompts into virtual worlds and logically move game characters within them. At first glance, this is particularly interesting for video games. However, the researchers believe that their approach with Genie could be an important step toward world models for robotics applications.
Foundation model for 2D platformers
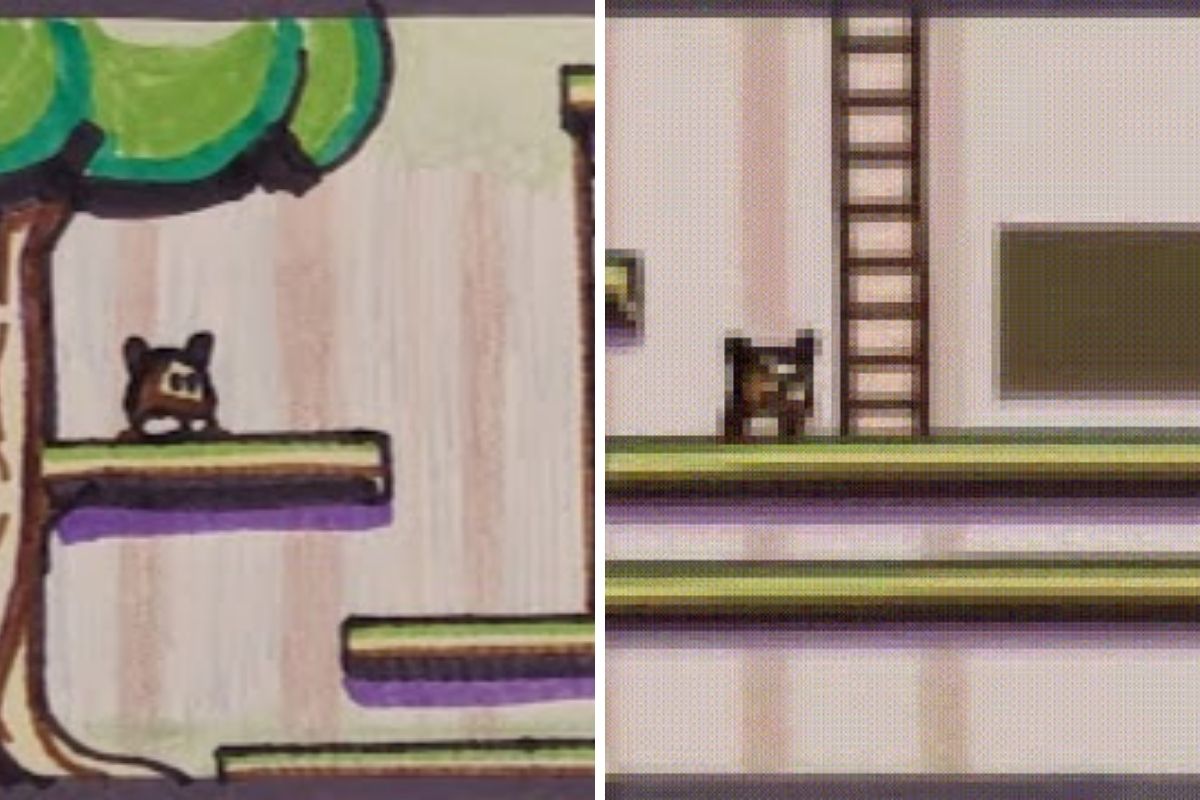
In its largest form, Genie is an 11-billion-parameter AI model that has the properties of a foundation model for 2D platformers: Given a visual input that is completely unknown to the model and a human-specified action that is roughly equivalent to pressing a gamepad button, Genie generates a virtual world in which the action is performed.

The actual actor, i.e. the sword-wielding hero or a ball in a hand-drawn sketch, is not fixed - the model has learned through training which elements in an image usually perform actions and then move them independently. Another interesting observation: Genie even takes into account the parallax effect that occurs when the foreground and background move at different speeds in a game.

Unlabeled gaming videos from the internet as training material
The special feature of the model is that it learns exclusively from videos - i.e. it does not receive any other information such as gamepad inputs during training. A collection of originally 200,000 hours of freely available game videos from the Internet served as the basis, which the researchers filtered down to 30,000 hours of material specifically for 2D platforms.
Genie consists of three components: a video tokenizer that generates tokens from frames, a latent action model that predicts actions between frames, and a dynamics model that predicts the next frame of the video. For the latent action model, the team limits the number of predicted actions to a small, discrete set of codes to enable human playability and further improve controllability.

Genie uses "spatiotemporal (ST) transformers" for its components. As is often the case with transformers, the team found that Genie's performance improved as the number of parameters increased.

Genie is a framework that works outside of 2D platformers
The team trained a smaller model with 2.5 billion parameters using videos of robotic arms. Genie impressively demonstrated its ability to imagine a coherent environment and reproduce inputs such as specific motion sequences. Genie even simulates the deformation of objects.
Video: Tim Rocktäschel/X
The team believes that the experiment shows that the method underlying Genie can be used to train a basic robotics model with larger video datasets. This could generate simulations that can be controlled at a low level and used for a variety of applications, such as training robotic agents.
Researchers exercise caution
Genie thus lays an important foundation for further research. Thanks to its general approach, the model could be trained on an even larger amount of Internet videos to simulate more realistic and coherent environments. Currently, the model's weak point is a very limited memory of 16 frames and a speed of only one frame per second in the new generations.
Genie could enable a large amount of people to generate their own game-like experiences. This could be positive for those who wish to express their creativity in a new way, for example children who could design and step into their own imagined worlds. We also recognize that with significant advances, it will be critical to explore the possibilities of using this technology to amplify existing human game generation and creativity—and empowering relevant industries to utilize Genie to enable their next generation of playable world development.
From the paper
Similar to OpenAI's Sora, Google DeepMind has chosen not to release model code or weights.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.