CosmicMan is a new AI image model optimized for generating images of people

Researchers at the Shanghai AI Laboratory have developed a specialized text-to-image model for photorealistic generation of human images. Thanks to a massive dataset and a new training method, CosmicMan achieves impressive results.
Scientists at the Shanghai AI Laboratory present CosmicMan, a novel text-to-image foundation model that specializes in generating high-quality images of people.
Unlike current image foundation models, which often struggle to generate detailed human images that match the text description, CosmicMan enables photorealistic results with precise text-image alignment. Users can even specify small details in their prompt, such as an alternative color for a hat.
Data production as a feedback loop between humans and AI
According to the researchers, led by Shikai Li and Jianglin Fu, CosmicMan's success rests on two pillars: a huge, high-quality dataset and a novel framework for training the AI model.
For CosmicMan, the scientists developed a new approach to generating training data that they call "Annotate Anyone." It works as a kind of feedback loop between humans and the AI, and aims to provide high-quality, always-up-to-date data at low cost. In this approach, the AI first generates detailed labels, which are then reviewed and optimized by humans.
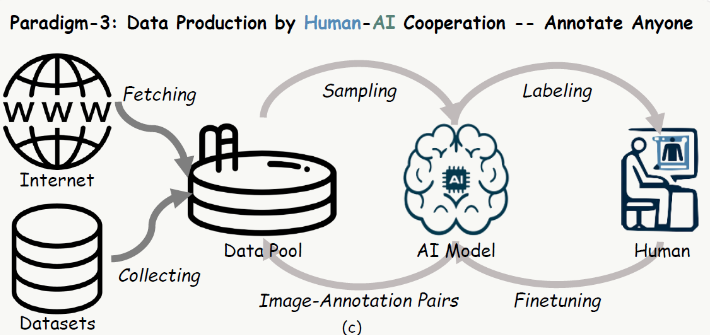
Using this method, the team created the "CosmicMan-HQ 1.0" dataset, which contains six million images of humans at an average resolution of 1488 x 1255 pixels. The images are annotated with precise text descriptions derived from 115 million attributes of varying levels of detail.
Focusing on the human
A second element is the so-called "Decomposed-Attention-Refocusing" framework (Daring), which, simply put, categorizes the words in a prompt into categories corresponding to the human body, such as "head," "arms," "legs," and so on.
This allows the AI model to focus on drawing each part of the person individually, rather than trying to draw everything at once. This leads to better and more easily customizable results.

In various experiments, CosmicMan shows promising results, outperforming current state-of-the-art models in both quantitative metrics and perceived visual quality, the researchers say. They see great potential for using CosmicMan in various applications, such as the entertainment industry, e-commerce, or avatar creation for virtual worlds.
The CosmicMan-HQ 1.0 dataset will be released soon. The team, led by Shikai Li and Jianglin Fu, will continue to improve the model and is already planning the next version.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.