LLMs hit a wall when processing complex information from lengthy texts

While providers of large language models (LLMs) tout their ability to process vast amounts of data, a new benchmark shows these models struggle to reliably understand and use information from lengthy texts.
Current tests like the "Needle In A Haystack" (NIAH) benchmark, used by companies like Google and Anthropic, show LLMs have impressive accuracy for finding information in long texts. But they don't evaluate how well the models actually comprehend the full context or summarize the meaning of lengthy documents.
In practice, depending on the use case, there are often more efficient search functions for large text data than LLMs, such as a simple keyword search using "Ctrl + F".
Researchers from the Shanghai AI Laboratory and Tsinghua University now present NeedleBench, a new bilingual (English and Chinese) benchmark that more comprehensively evaluates the contextual capabilities of LLMs.
It includes various tasks that test LLMs' information extraction and reasoning abilities in long texts. NeedleBench covers several length intervals (4k, 8k, 32k, 128k, 200k, 1000k, and beyond) and different text depth ranges.
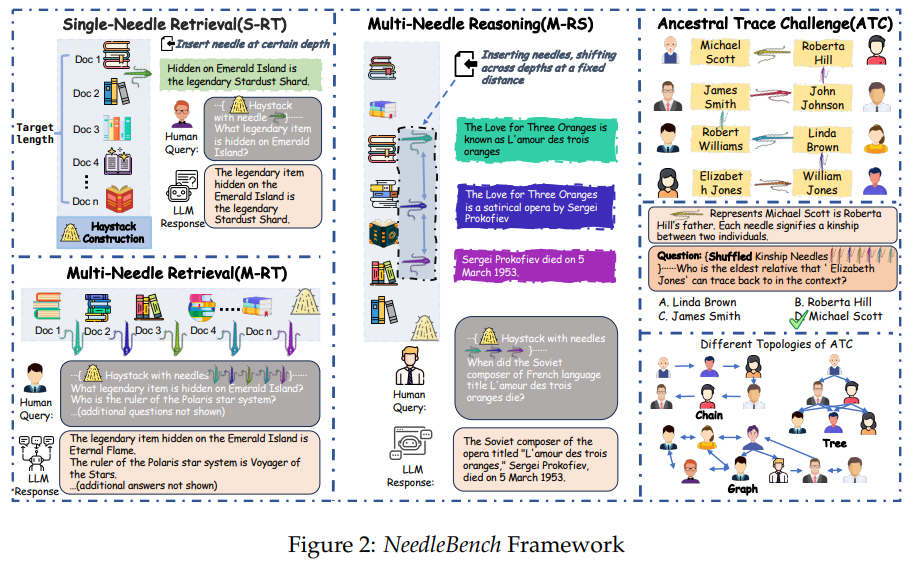
The Multi-Needle Reasoning Task (M-RS) is particularly interesting. It describes what language models are expected to do: draw meaningful conclusions from scattered information in large documents, considering all the data, to answer complex questions.
The researchers performed these M-RS tasks with several open-source models, showing that there is a massive gap between mere retrieval and actual reasoning via a context window.
To stress test the context-dependent performance of large API models, the researchers developed the Ancestral Trace Challenge (ATC), in which the model must correctly describe the kinship relationships of individuals using various textual data. The goal is to test the ability of LLMs to handle multi-level logical challenges that may occur in real-world scenarios with long contexts.
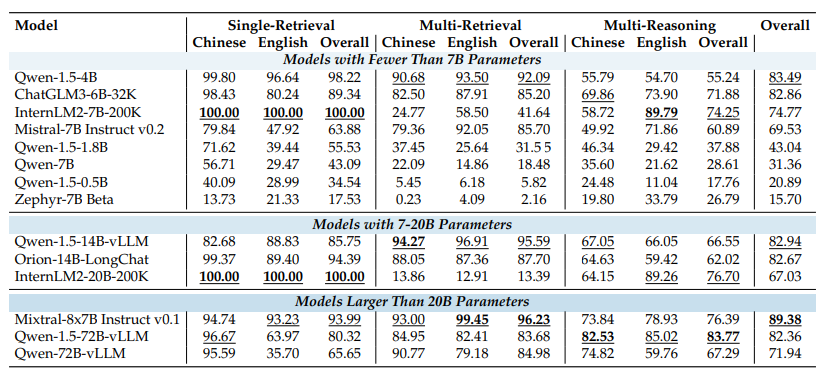
GPT-4-Turbo and Claude 3 models performed best in the Ancestral Trace Challenge. However, their performance also declined rapidly as the amount of data and task complexity increased. Among the open-source models, the large language model DeepSeek-67B performed best.
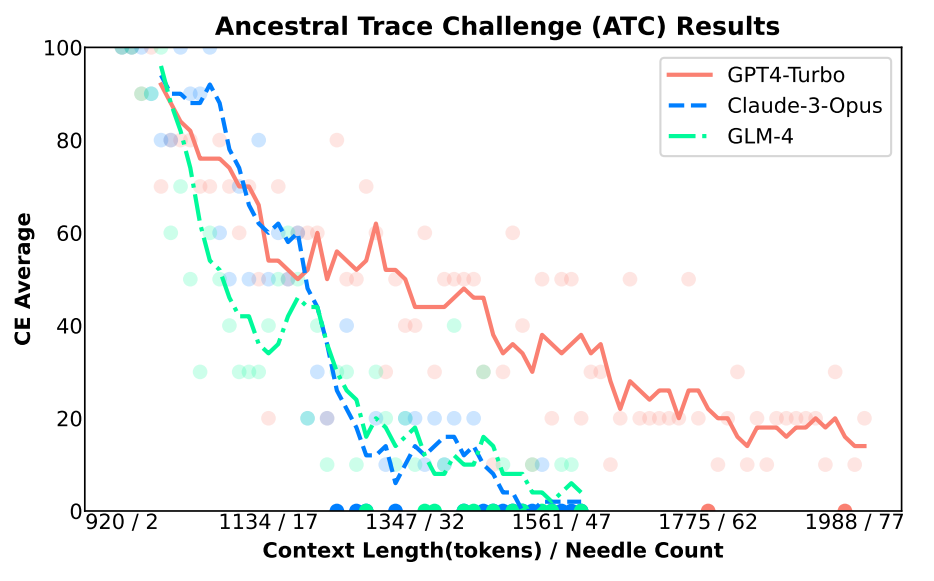
While companies like Google claim to be able to process over a million tokens, which is technically true, NeedleBench shows that the models reach their limits with only a few thousand tokens when it comes to extracting complex information from long texts and linking it logically. At least this seems to be true for text, different rules may apply for video and audio.
In any case, the study shows the need for a more nuanced evaluation of LLM capabilities, especially as these models are increasingly applied to real-world tasks involving large amounts of data, and people may simply believe that the answers they receive are correct and comprehensive.
"Our results suggest that current LLMs have significant room for improvement in practical long-context applications, as they struggle with the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks," the researchers conclude. Scripts, code, and datasets are available on Github.
Interesting sub-findings from the study include: many open-source models generally perform slightly better when the source content precedes the prompt, chain-of-thought prompting improves results, and larger models generally solve tasks better.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.