A new study shows that large language models benefit from longer reasoning steps in chain-of-thought prompts — even when they contain incorrect information.
"Chain of thought" prompting has been shown to improve the reasoning abilities of large language models. Now, a study by researchers at Northwestern University, the University of Liverpool, the New Jersey Institute of Technology, and Rutgers University shows that the length of reasoning steps in CoT prompts is directly related to the performance of language models in complex problem-solving tasks.
The study shows that simply lengthening the reasoning steps within prompts, without adding new information, significantly improves the reasoning ability of language models. Conversely, shortening the reasoning steps, even if the core information is retained, leads to a significant deterioration in reasoning performance.
They tested a wide range of task types, including arithmetic, common sense, symbolic, and more specific sets such as MultiArith, GSM8K, AQuA, SingleEq, SVAMP, or StrategyQA.
One of the most surprising results of the study: even incorrect rationales can lead to positive results if they are long enough. This suggests that the length of the reasoning steps has a greater influence than the factual correctness of the individual steps, the researchers conclude.
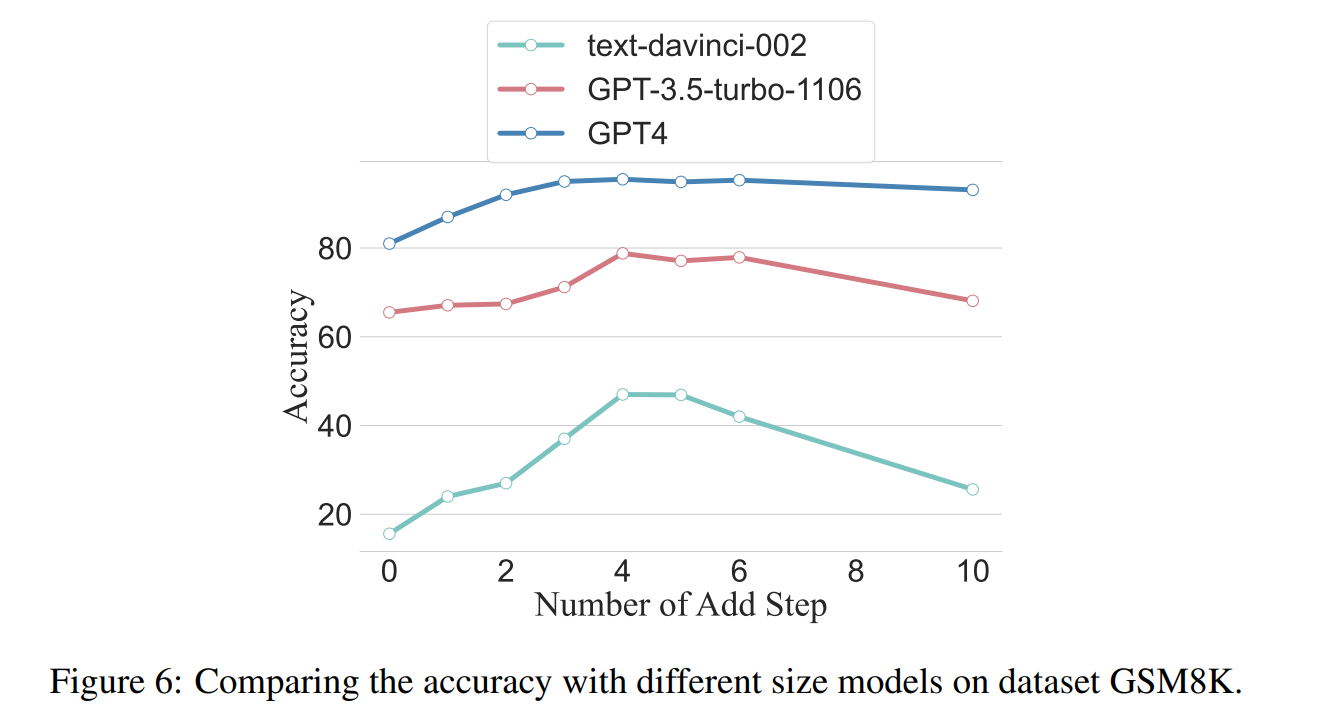
Even GPT-4 shows better performance with longer reasoning steps
However, longer reasoning steps do not always help - they are task-dependent. The study found that simpler tasks benefit less from additional steps, while more complex tasks are significantly improved by longer chains of reasoning. Larger models, such as GPT-4, also showed a higher tolerance for the length or brevity of steps - smaller models benefited most from the strategy in the tests. However, chains that are too long can degrade performance again, especially for smaller models.
The team now plans to continue their research and analyze the neural activation patterns between long and short reasoning steps to better understand how the length of reasoning steps affects language models.