T-FREE: Researchers develop tokenizer-free method for more efficient AI language models
With T-FREE, a research team presents a new method that does not require a tokenizer and could significantly increase the efficiency of large language models.
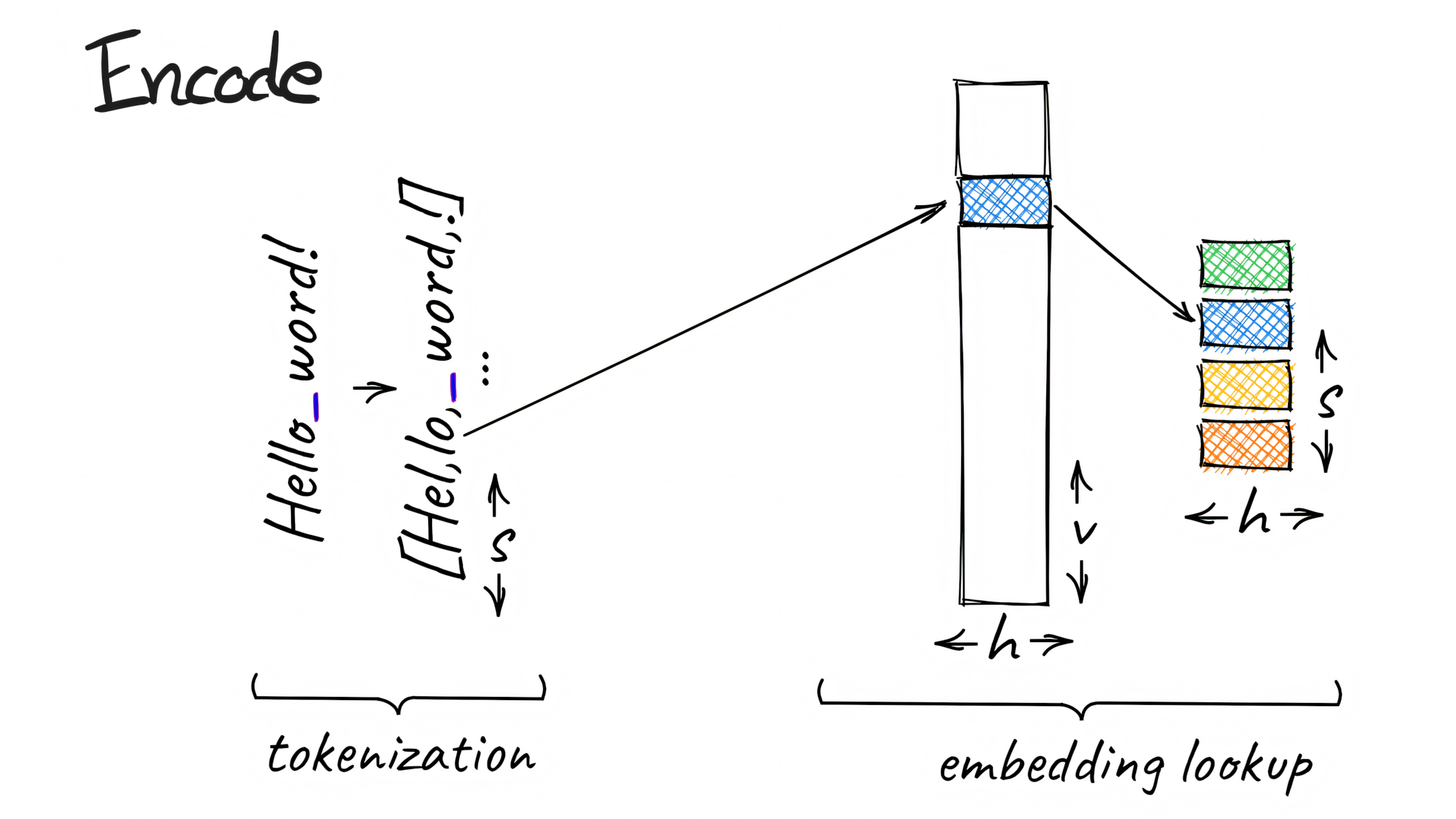
Scientists from Aleph Alpha, the Technical University of Darmstadt, hessian.AI, and the German Research Center for Artificial Intelligence (DFKI) created T-FREE, which stands for "Tokenizer-Free Sparse Representations for Memory-Efficient Embeddings." Instead of using traditional tokenization, T-FREE directly embeds words through sparse activation patterns using character triples, which the team calls "trigrams." This approach allows for substantial compression of the embedding layer, which is responsible for converting text into numerical representations.
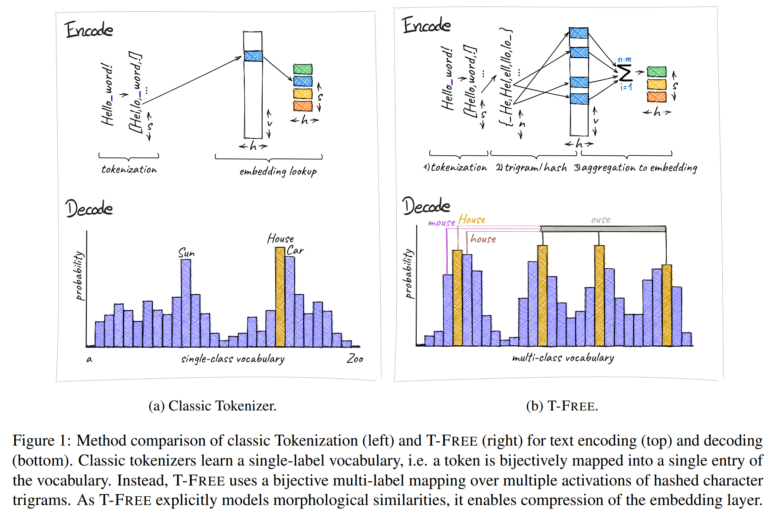
In initial tests, the researchers achieved a parameter reduction of over 85 percent in these layers using T-FREE, without compromising performance in downstream tasks such as text classification or question-answering systems.
T-FREE facilitates transfer learning
One of the main advantages of T-FREE is its explicit modeling of morphological similarities between words. This means that similar word forms like "house," "houses," and "domestic" can be represented more efficiently in the model, as their similarities are directly incorporated into the coding. The researchers argue that the embeddings of such similar words should remain close to each other and can therefore be highly compressed. As a result, T-FREE can not only reduce the size of the embedding layers but also decrease the average encoding length of the text by 56 percent.
Additionally, T-FREE shows significant improvements in transfer learning between different languages. In an experiment with a 3-billion-parameter model trained first on English and then on German, T-FREE demonstrated much better adaptability than conventional tokenizer-based approaches.
However, the researchers acknowledge some limitations of their study. For example, the experiments have so far only been conducted with models of up to 3 billion parameters. Evaluations with larger models and training datasets are planned for the future.
More information about T-FREE is available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.