Study questions benefits of LLMs large context windows

Should LLMs store information externally and retrieve it via RAG, or should users insert it directly into prompts using large context windows? A new study provides guidance.
Context windows for large language models have expanded rapidly in recent years. While GPT-3 could only process about 2,000 tokens per prompt, the latest OpenAI model GPT-4o handles up to 128,000. Magic AI even claims a 100 million token context window for its newly unveiled model. This growth has led some to question the need for Retrieval Augmented Generation (RAG), which typically stores information in a vector database and retrieves it dynamically for each query.
A new study by Nvidia researchers challenges the assumption that Retrieval Augmented Generation (RAG) is unnecessary as context windows in large language models (LLMs) continue to grow. The study shows that, when combined with a specific mechanism, RAG can outperform LLMs with large context windows.
The researchers propose an order-preserving RAG approach (OP-RAG) that maintains the original order of retrieved chunks in the LLM context, unlike conventional RAG methods that typically arrange chunks in descending order of relevance.
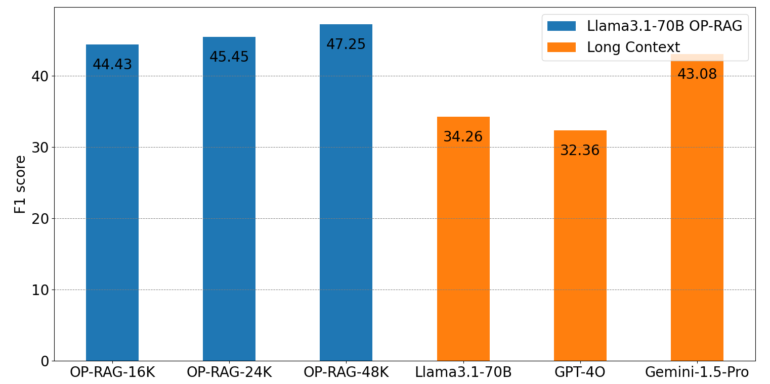
RAG clearly outperforms long context
Using the En.QA and En.MC datasets of the ∞Bench benchmark, designed for long-context question-answer tasks, the researchers found that OP-RAG with the LLaMA 3.1-70B model achieved an F1 score of 44.43 while using only 16,000 retrieved tokens. In comparison, the same model without RAG, using its full 128,000-token context window, only achieved a score of 34.32. GPT-4o and Gemini-1.5-Pro without RAG achieved F1 scores of 32.36 and 43.08, respectively.
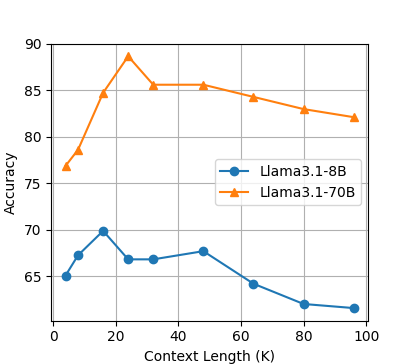
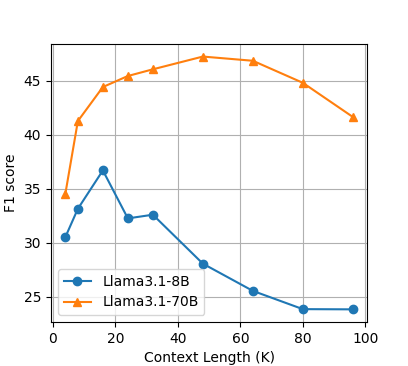
The study also investigated the impact of context length on OP-RAG performance, revealing that response quality initially improved with increasing context length but then decreased. The researchers attribute this to the trade-off between retrieving potentially relevant information and introducing irrelevant or distracting information. They found that the optimal balance maximizes response quality, and including too much irrelevant information beyond this point degrades the model's performance.
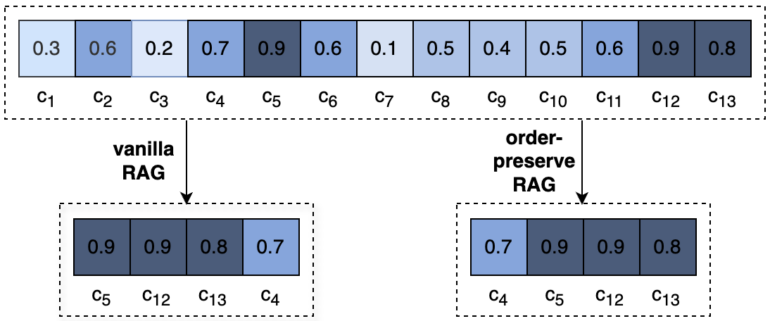
Correct order improves RAG retrieval
When comparing OP-RAG with conventional RAG, the researchers discovered that OP-RAG performed significantly better when retrieving a large number of chunks. For example, on the En.QA dataset, OP-RAG achieved an F1 score of 44.43 when retrieving 128 chunks, while conventional RAG only achieved a score of 38.40.
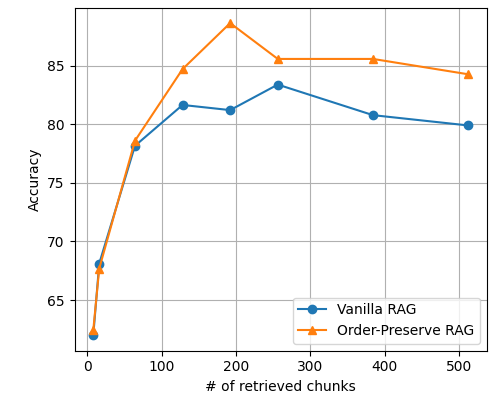
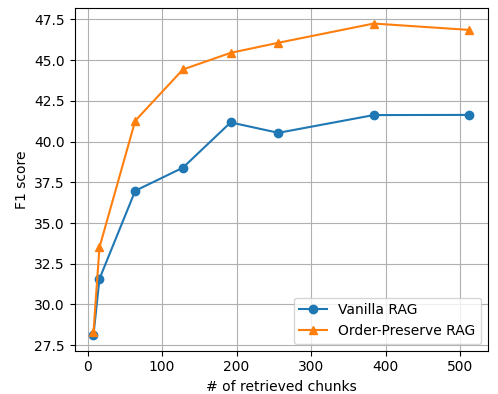
These results contradict previous research, such as a paper by Li et al. from July 2024, which argued that long-context LLMs would consistently outperform RAG approaches in terms of response quality.
The introduction of language models with large context windows has always been met with criticism. Even if models theoretically accept hundreds of thousands of tokens as a prompt, information from the middle is often lost, a phenomenon known as "lost in the middle." Despite progress in this area, the problem does not appear to be fully resolved. Models with smaller context windows also have the advantage of lower energy consumption, among other benefits.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.