Researchers put OpenAI's o1 through its paces, exposing both breakthroughs and limitations

A new study independently examines the planning abilities of OpenAI's latest AI model, o1. While the results show major improvements over traditional language models, significant limitations remain.
Researchers at Arizona State University tested o1's planning capabilities using the PlanBench benchmark. Their findings reveal that this "Large Reasoning Model" (LRM) makes substantial progress compared to conventional large language models (LLMs), but still falls short of solving tasks completely.
Developed in 2022, PlanBench evaluates AI systems' planning abilities. It includes 600 tasks from the "Blocksworld" domain, where blocks must be stacked in specific orders.
O1 achieved 97.8% accuracy on Blocksworld tasks, vastly outperforming the previous best language model, LLaMA 3.1 405B, which only solved 62.6%. On a more challenging encrypted version called "Mystery Blocksworld," o1 reached 52.8% accuracy while conventional models almost entirely failed.
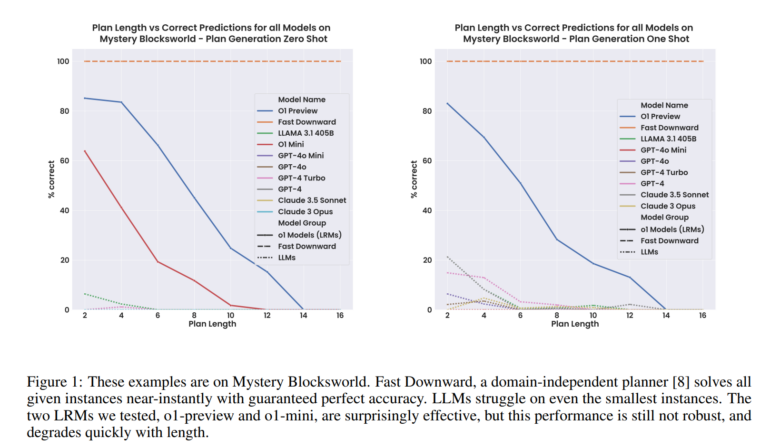
The researchers also tested a new randomized variant to rule out the possibility that o1's performance stemmed from having benchmark data in its training set. O1's accuracy dropped to 37.3% on this test but still far exceeded older models, which scored near zero.
Performance drops significantly with more planning steps
Performance declined sharply as tasks grew more complex. On problems requiring 20 to 40 planning steps, o1's accuracy in the simpler test fell from 97.8% to just 23.63%.
The model also struggled to identify unsolvable tasks, correctly recognizing them only 27% of the time. In 54% of cases, it incorrectly generated complete but impossible plans.
"Quantum improvement" - but not robust
While o1 shows a "quantum improvement" in benchmark performance, it offers no guarantees for solution correctness. Classic planning algorithms like Fast Downward achieve perfect accuracy with much shorter computation times.
The study also highlights o1's high resource consumption. Running the tests cost nearly $1,900, whereas classic algorithms can run on standard computers at virtually no cost.
The researchers stress that fair comparisons of AI systems must consider accuracy, efficiency, costs, and reliability. Their findings show that while AI models like o1 are progressing in complex reasoning tasks, these capabilities are not yet robust.
"Over time, LLMs have improved their performance on vanilla Blocksworld–with the best performing model, LlaMA 3.1 405B, reaching 62.5% accuracy. However, their dismal performance on the obfuscated ("Mystery") versions of the same domain betrays their essentially approximate retrieval nature. In contrast, the new o1 models, which we call LRMs (Large Reasoning Models)–in keeping with OpenAI’s own characterizations–not only nearly saturates the original small instance Blockworld test set, but shows the first bit of progress on obfuscated versions. Encouraged by this, we have also evaluated o1’s performance on longer problems and unsolvable instances, and found that these accuracy gains are not general or robust."
From the paper.
The code for PlanBench is available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.