OpenAI's o1 probably does more than just elaborate step-by-step prompting

OpenAI's latest language model, o1, appears to offer more than just improved step-by-step reasoning capabilities.
OpenAI claims to have found a way to scale AI capabilities by scaling inference processing power. By taking advantage of increased computational resources and allowing for longer response times, 01 is expected to deliver superior results. This would open up new possibilities for AI scaling.
While the model was trained from scratch using the popular step-by-step inference method, its improved performance is likely due to additional factors.
Researchers at Epoch AI recently attempted to match the performance of o1-preview on a challenging scientific multiple-choice benchmark called GPQA (Graduate-Level Google-Proof Q&A Benchmark).
They used GPT-4o with two prompting techniques (Revisions and Majority Voting) to generate a large number of tokens, similar to o1's "thought process".
The results showed that while generating more tokens led to slight improvements, no amount of tokens could come close to o1-preview's performance. Even with a high token count, GPT-4o variants' accuracy remained significantly lower than o1-preview's.
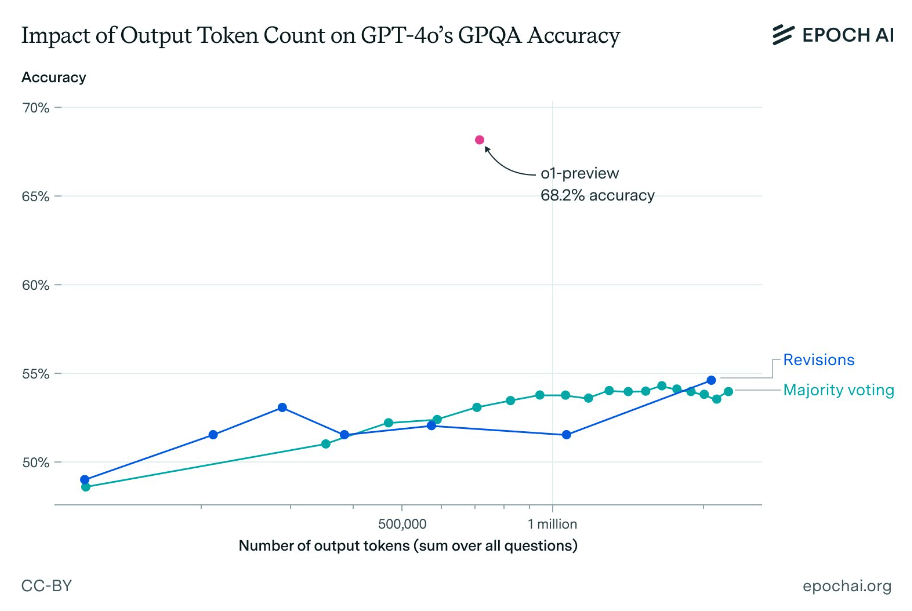
This performance gap persisted even when accounting for o1-preview's higher cost per token. Epoch AI's extrapolation suggests that spending $1,000 on output tokens with GPT-4o would still result in accuracy more than 10 percentage points below o1-preview.
What is o1's secret sauce?
The researchers conclude that simply scaling up inference processing power is not enough to explain o1's superior performance. They suggest that advanced reinforcement learning techniques and improved search methods are likely to play a key role, underlining the role of algorithmic innovation in AI progress.
However, the study's authors note that their findings don't definitively prove algorithmic improvements are the sole factor behind o1-preview's edge over GPT-4o. Higher quality training data could also contribute to the performance difference.
Because o1 has been trained directly on correct reasoning paths, it could also be more efficient at following learned logical steps that lead to correct results more quickly, potentially making better use of available computing power.
Separately, researchers at Arizona State University found that while o1 shows significant progress in planning tasks, it remains prone to errors. Their study revealed improved performance on logic benchmarks but noted that o1 offers no guarantee of correct solutions. In contrast, traditional planning algorithms achieved perfect accuracy with shorter computation times and lower costs.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.