'OCR 2.0' model converts images of text, formulas, notes, and shapes into editable text

Researchers have created a new universal optical character recognition (OCR) model called GOT (General OCR Theory). Their paper introduces the concept of OCR 2.0, which aims to combine the strengths of traditional OCR systems and large language models.
According to the researchers, an OCR 2.0 model uses a unified end-to-end architecture and requires fewer resources than large language models, while being versatile enough to recognize more than just plain text.
GOT's architecture consists of an image encoder with approximately 80 million parameters and a speech decoder with 500 million parameters. The encoder compresses 1,024 x 1,024 pixel images into tokens, which the decoder then converts into text of up to 8,000 characters.
'OCR 2.0' unlocks automated processing of complex visual data in science, music, and analytics
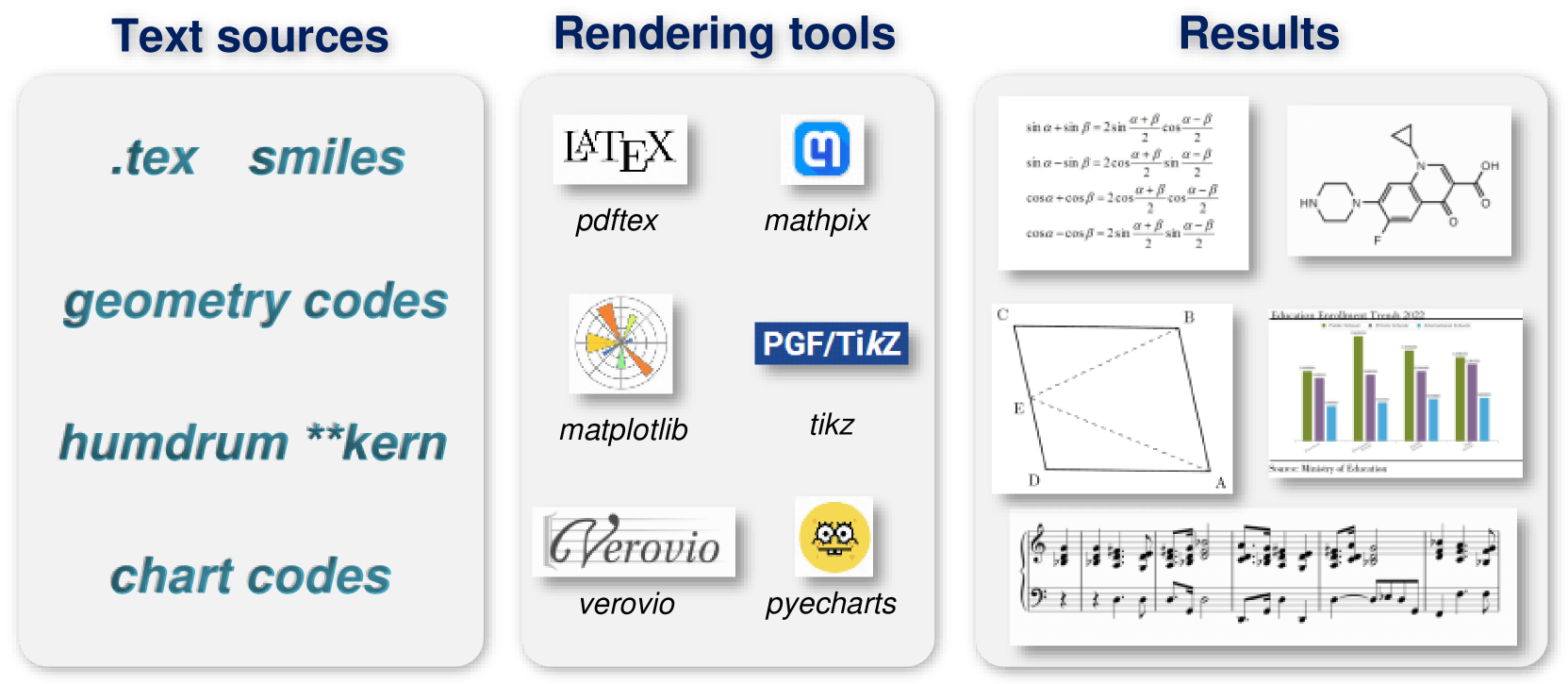
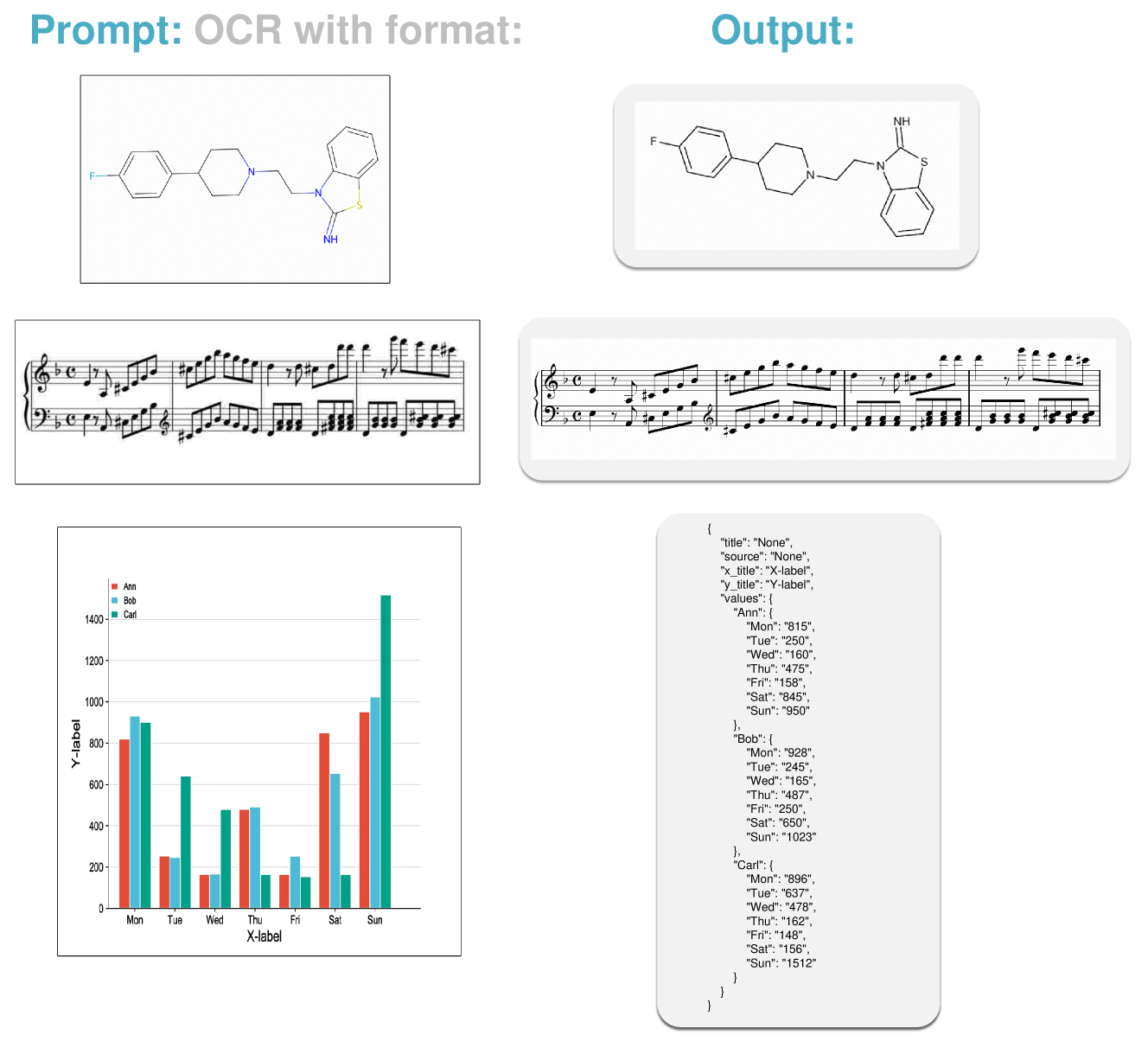
The new model can recognize and convert various types of visual information into editable text. These include scene text and document text in English and Chinese, mathematical and chemical formulas, musical notes, simple geometric shapes, and diagrams with their components.
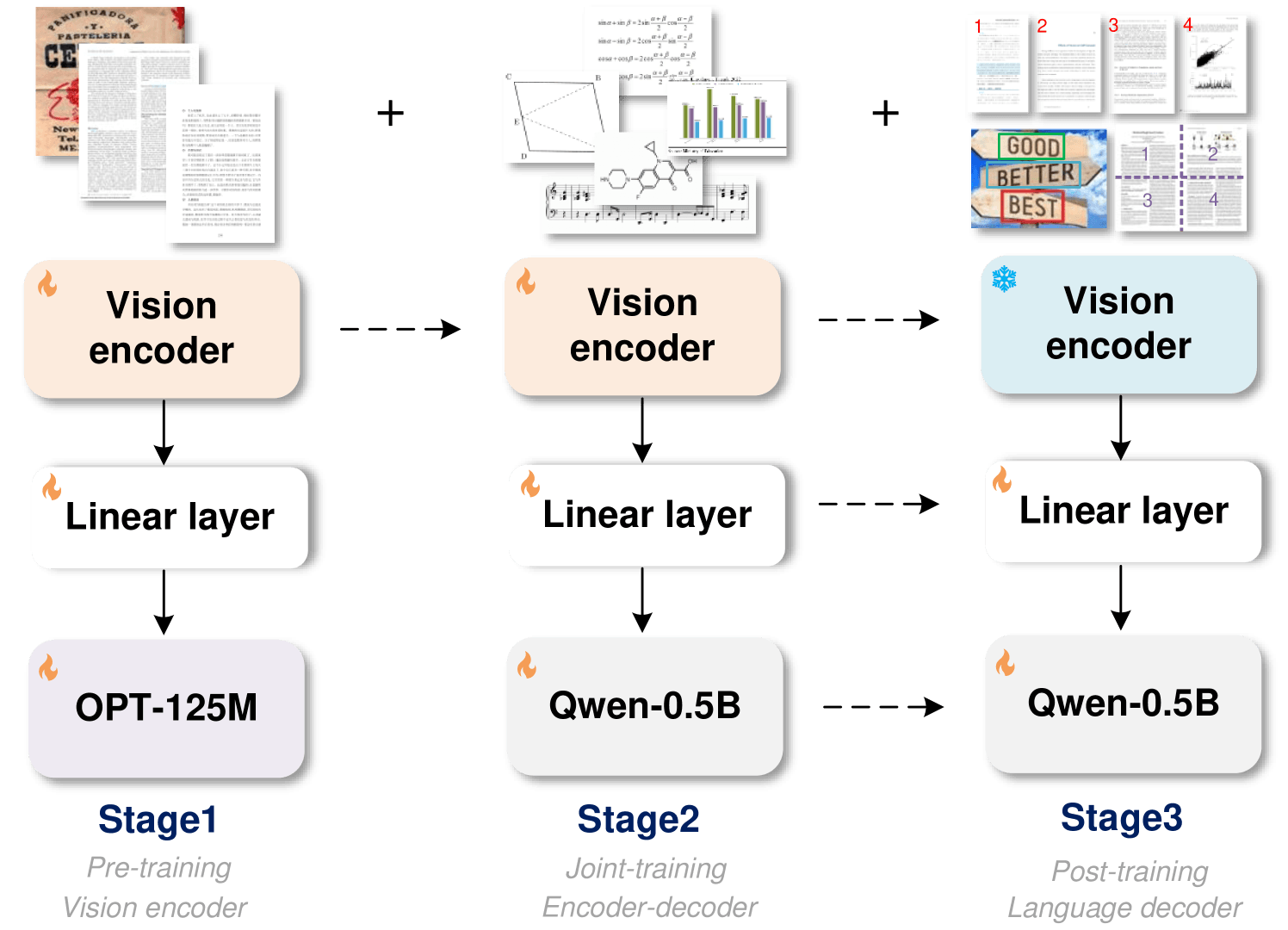
To optimize training, the researchers first trained only the encoder on text recognition tasks. They then added Alibaba's Qwen-0.5B as a decoder and fine-tuned the entire model with diverse, synthetic data. The team used rendering tools such as LaTeX, Mathpix-markdown-it, TikZ, Verovio, Matplotlib, and Pyecharts to generate millions of image-text pairs for training.

The researchers report that GOT's modular design and synthetic data training allow for flexible expansion. New capabilities can be added without retraining the entire model. This approach allows for efficient updates and improvements to the system over time, they say.
In experiments, GOT performed well across various OCR tasks. It achieved top scores in document and scene text recognition, even outperforming specialized models and large language models in diagram recognition.
The researchers have made a free demo and the code available on Hugging Face for others to use and build upon.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.