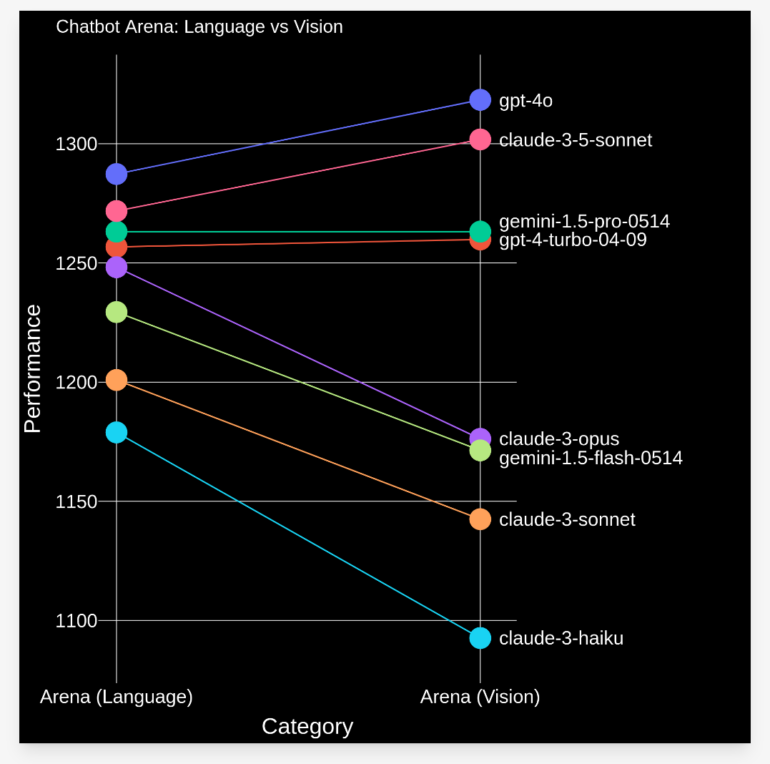
LMSYS Org has added image recognition to the Chatbot Arena to compare vision language models (VLMs) from OpenAI, Anthropic, Google, and other AI vendors. In two weeks, more than 17,000 user preferences were collected in more than 60 languages. GPT-4o and Claude 3.5 Sonnet performed significantly better at image recognition than Gemini 1.5 Pro and GPT-4 Turbo. While Claude 3 Opus is better than Gemini 1.5 Flash for language models, both are similarly good for VLMs. The open-source model Llava-v1.6-34b is slightly better than Claude-3-Haiku. The data collected shows common applications such as image description, math problems, document comprehension, meme explanation, and story writing. Next, the team plans to add support for multiple images, as well as PDFs, video, and audio. The Large Model Systems Organization (LMSYS Org) is an open research organization founded by UC Berkeley students and faculty in collaboration with UCSD and CMU.