In-context learning proves competitive with LLM fine-tuning when data is scarce

Researchers at the École Polytechnique Fédérale de Lausanne (EPFL) have conducted a thorough analysis comparing in-context learning (ICL) and instruction fine-tuning (IFT) for adapting large language models (LLMs).
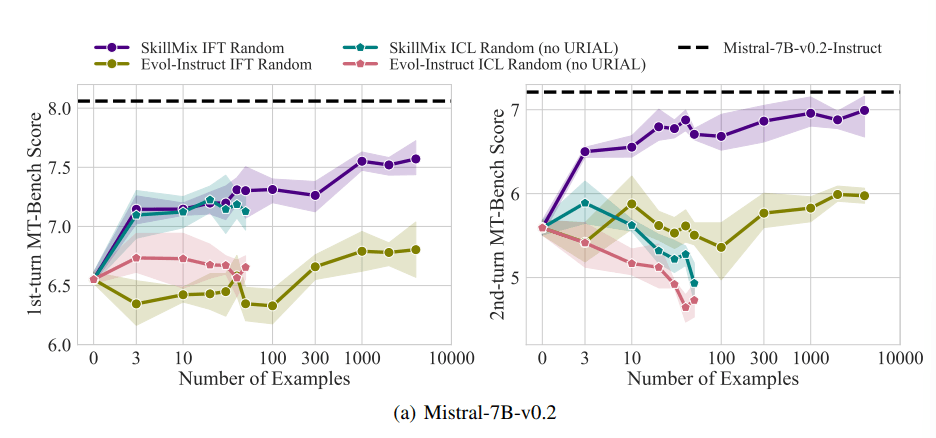
The study used the industry standard MT-Bench benchmark to measure how well models follow instructions. Surprisingly, ICL and IFT performed similarly when fewer training examples (up to 50) were used in the first run of the MT-Bench test.
The study authors suggest that when only a few examples are available, ICL with high-quality data could be a viable alternative to IFT.
Instruction fine-tuning is better for more complex tasks
Despite similarities in simple tasks, clear differences emerged between the two methods in more complex scenarios. In multi-round conversations, IFT significantly outperformed ICL.
The researchers hypothesize that this is because ICL models overfit to the style of individual examples and struggle to respond to more complex conversations. Even base models were able to outperform ICL in this second round.
The study also investigated the URIAL method, which trains base language models with just three examples and instruction-following rules. Although URIAL produced good results, it fell short of models adapted through instruction fine-tuning.
The EPFL researchers improved URIAL's performance to approach that of fine-tuned models by selecting additional optimized examples. This was done using a greedy search, which selects examples that incrementally improve the model's performance the most. The result underscores the general importance of high-quality training data for both ICL and IFT, and even for training the base models.
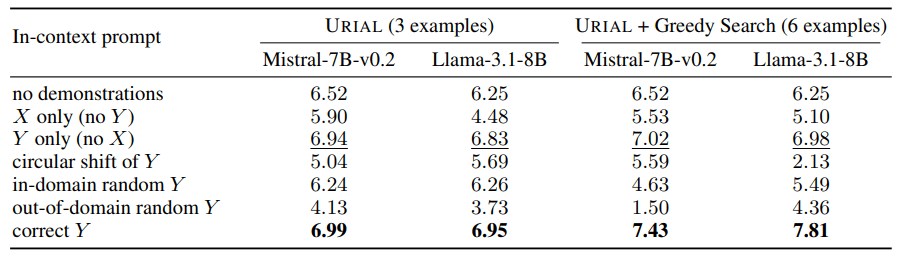
Another finding was the significant impact of decoding parameters on model performance. These parameters, which determine how the model generates text, played a critical role in both base LLMs and models using URIAL. With the right decoding parameters, even base models can follow instructions to some extent, the researchers note.
Implications for practice
The results show that in-context learning can effectively and quickly adjust language models, especially when few training examples are available.
However, fine-tuning remains superior for generalizing to more complex tasks such as multi-turn conversations. In addition, IFT continues to improve with larger datasets, while ICL plateaus after a certain number of examples.
The researchers emphasize that choosing between ICL and IFT depends on various factors, including available resources, data quantity, and specific application requirements. In any case, the study highlights the importance of high-quality training data for both approaches.
The study, titled "Is In-Context Learning Sufficient for Instruction Following in LLMs?" will be presented at NeurIPS 2024. The code is available on Github.
The gold standard may still be to first achieve high-quality generation as quickly as possible with examples in the prompt (ICL), which can then be further optimized and stabilized by fine-tuning (IFL).
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.